
「llama.cppは設定が複雑」「Ollamaは便利だけどUIが弱い」「LM Studioは画像生成までは扱えない」――そんな不満を1本のEXEで解消できるのがKoboldCppです。LostRuins氏が開発するオープンソースの統合推論ランタイムで、たった1ファイルをダウンロードして起動するだけで、GGUF形式のLLM推論はもちろん、Stable Diffusion 1.5 / SDXL / SD3 / FLUXによる画像生成、Whisperによる音声認識、LTX2.3による動画生成、AceStep 1.5による音楽生成まで、ローカルAIに必要なすべての機能を1つのプロセスで動かせます。
本記事は2026年6月17日時点の最新版「v1.115.2」(2026年6月12日リリース)に基づき、Windows / Linux / macOSすべての環境でゼロから実用ワークフローを組み立てるまでを徹底解説します。Anthropic互換APIの追加、Gemma 4対応、MTP(Multi-Token Prediction)対応など、直近の重要アップデートも漏らさずカバーします。読者がこの1記事だけで完結できる決定版として執筆しました。
KoboldCppとは何か
KoboldCppは「Run GGUF models easily with a KoboldAI UI. One File. Zero Install.」をスローガンに掲げる、GGML / GGUF形式モデル向けの統合推論エンジンです。GitHubリポジトリはLostRuins/koboldcppで公開されており、2023年4月の初回リリース以来、コミュニティドリブンで機能拡張を続けています。
本体はllama.cppとstable-diffusion.cppをベースとしていますが、それらに大量のラッパー機能・Web UI・OpenAI互換APIを乗せ、エンドユーザーが「ダブルクリックだけで使える状態」にパッケージングしたものと考えるとイメージしやすいでしょう。
主な特徴
- シングルバイナリ配布:Windows用
koboldcpp.exe、Linux用koboldcpp-linux-x64、macOS用koboldcpp-mac-arm64のいずれも単一実行ファイル。Python環境構築は不要 - CUDA / Vulkan / Metal / ROCm対応:NVIDIA / AMD / Intel / Apple Silicon、ほぼすべてのGPUで動作
- マルチモーダル統合:テキスト生成・画像生成・画像理解・音声認識(Whisper)・音声合成(TTS)・動画生成(LTX2.3)・音楽生成(AceStep 1.5)まで1つのプロセスで完結
- KoboldAI Lite UI内蔵:チャットモード・物語生成モード・アドベンチャーモード・インストラクションモードを切替可能なリッチなWebフロントエンド
- OpenAI / Anthropic互換APIエンドポイント:既存のクライアントツールからほぼ無改変で接続可能
- 後方互換性重視:過去の全GGML / GGUFモデルをサポート(llama.cpp本家がときどき切り捨てる古い量子化形式も継続サポート)
ライセンス
KoboldCpp本体のコードはAGPL v3.0、組み込んでいるllama.cppとstable-diffusion.cppはMIT Licenseです。個人利用・社内利用は完全に自由で、改変版をネットワーク経由で配信する場合のみソース公開義務が発生します。
最新リリース情報(2026年最新)
2026年6月17日時点での最新版はv1.115.2(2026年6月12日リリース)です。KoboldCppは月2回前後のペースで安定リリースを継続しており、直近6ヶ月だけでもAnthropic API互換・Gemma 4対応・MTP・連続バッチング・LTX2.3動画生成など、ローカルAI業界の最新動向を即座に取り込んでいます。
直近6ヶ月のリリース履歴
| バージョン | リリース日 | 主要アップデート |
|---|---|---|
| v1.115.2 | 2026-06-12 | Anthropic /v1/messages API完全対応(マルチモーダル・ツール呼び出し含む)、Gemma 4 UV (12B) 対応、MTP / Gemma Assistantモデル対応、動画生成のリファレンス画像システム刷新(開始フレーム+終了フレーム指定可) |
| v1.114.1 | 2026-05-30 | 連続バッチング(実験的)による並列テキスト生成、RPCバックエンドで複数マシンのGPU分散推論、LTX2.3動画生成、新規画像モデル4種(Lens / HiDream o1 / LongCat / Ernie)対応 |
| v1.113.2 | 2026-05-16 | テンソル分割(split mode)再構築、ランタイムでの画像LoRAディレクトリ切替、RNN / ハイブリッドモデル向けSmartCache改善 |
| v1.112.2 | 2026-04-20 | AceStepXL音楽生成モデル対応、思考モデル向けreasoning budget / effort制御、q5_1 KVキャッシュ量子化、Jinjaツール呼び出しのストリーミング対応 |
| v1.111.2 | 2026-04-03 | Gemma 4(ビジョン対応)、Qwen3 TTS CustomVoice / VoiceDesign、/v1/responses / /v1/messages API基本対応 |
| v1.110 | 2026-03-19 | OpenAI互換ルーターモード(モデル自動ホットスワップ)、Qwen3 TTS 1.7B(音声クローン)、AceStep 1.5音楽生成(MP3出力対応) |
v1.115.2で追加された重要機能の詳細
最新のv1.115.2では、特に以下の3点が実務インパクトの大きいアップデートです。
- Anthropic Messages API完全互換:
POST /v1/messagesエンドポイントがClaude API互換となり、system/tools/ 画像入力(imageブロック)まで対応。Claude Code・Cline・Continueなど、Anthropic APIを前提に作られたクライアントから無改変で接続できます。 - MTP(Multi-Token Prediction)対応:起動オプション
--usemtpを有効化、もしくはドラフトモデルとしてgemma-4-26b-A4B-it-assistant-Q4_0.ggufを指定すると、メインモデルの推論を高速化できます。投機的デコーディングと同等の仕組みで、対応モデルでは10〜30%のスループット向上が報告されています。 - 動画生成リファレンス画像の刷新:SDUI Img2Imgで「特定フレームに終わる動画」が生成可能になり、txt2imにアップロードした2枚のリファレンス画像で「開始フレームと終了フレームを指定」できるようになりました。短尺ループ動画やシームレスな繋ぎ動画の制作が格段に楽になっています。
詳細なリリースノートは公式リリースページを参照してください。
他ツールとの比較
同じGGUF推論エンジンであっても、ツール選択で快適度が大きく変わります。代表的な4ツールと比較した表を以下にまとめます。バージョンはすべて2026年6月17日時点の公式リポジトリ確認値です。
| 項目 | KoboldCpp | llama.cpp | Ollama | LM Studio | text-generation-webui |
|---|---|---|---|---|---|
| 最新版 | v1.115.2 (2026-06-12) | b9672 (2026-06-16) | v0.30.9 (2026-06-15) | 0.4.16 | v4.9 (2026-05-20) |
| ライセンス | AGPL-3.0 | MIT | MIT | クローズド(無料) | AGPL-3.0 |
| 配布形態 | 単一EXE / バイナリ | ソース+llama-server | インストーラ / バイナリ | GUIインストーラ | Python+シェルスクリプト |
| 初期セットアップ難易度 | ★☆☆☆☆(最低) | ★★★★☆ | ★☆☆☆☆ | ★☆☆☆☆ | ★★★☆☆ |
| Web UI | KoboldAI Lite内蔵 | シンプルなチャットUI | なし(CLI / API) | 独自デスクトップGUI | Gradio UI(高機能) |
| OpenAI互換API | ○ | ○(llama-server) | ○ | ○ | ○ |
| Anthropic互換API | ○(v1.115以降) | × | × | × | × |
| 画像生成内蔵 | ○(SD1.5 / SDXL / SD3 / FLUX) | × | × | × | × |
| Whisper音声認識 | ○ | × | × | × | × |
| TTS音声合成 | ○(Qwen3 TTS / CustomVoice) | × | × | × | ○(拡張) |
| 動画生成 | ○(LTX2.3) | × | × | × | × |
| 音楽生成 | ○(AceStep 1.5 / XL) | × | × | × | × |
| マルチGPU分散 | ○(RPCバックエンド) | ○(RPC) | △ | × | ○ |
| カスタムバックエンド切替 | 1ツールで完結 | 不可 | 不可 | 不可 | 5バックエンド切替 |
使い分けの指針
- KoboldCpp:1台のPCでLLM・画像・音声・動画・音楽を全部やりたいクリエイター志向のユーザー。インストールが面倒くさいと感じる人
- llama.cpp:最低限の依存で最高速度を出したいエンジニア。サーバーやDocker環境への組み込み
- Ollama:「
ollama run llama3」のような最短コマンドだけで使いたい人。CLIワークフロー - LM Studio:純粋にチャット用途。デスクトップアプリの見た目を重視する人
- text-generation-webui:複数バックエンドを切替えてベンチマーク・LoRA訓練までやりたい研究者・上級者
メリット・デメリット
メリット
- 導入が圧倒的に簡単:EXE / バイナリをダウンロードしてダブルクリックするだけ。Python / Conda / CUDA Toolkitのインストールも不要
- 1プロセスでマルチモーダル完結:LLM・SD・Whisper・TTSのプロセスを別々に立ち上げる必要がない
- 低スペックPCでも動く:CPUオンリーでもLLM推論が可能。古いGPUでもVulkanで動作
- Web UIが豊富:チャット・物語・アドベンチャー・インストラクションの4モードを切替可能
- 後方互換性が極めて高い:本家llama.cppが古い量子化形式を切り捨てても、KoboldCppでは引き続き動作することが多い
- 更新が活発:月2回前後の安定リリース。新モデル対応の速さは業界トップクラス
- RPC分散推論:複数台のGPUを束ねて1つのモデルを動かせる
デメリット
- バイナリサイズが大きい:全機能入りのためEXEだけで数百MB~1GB超
- 本家llama.cppより若干遅い場合がある:抽象化レイヤー分のオーバーヘッドが乗ることがある(5〜10%程度)
- AGPL-3.0なのでSaaS組み込みは要注意:ネットワーク経由で改変版を提供する場合、ソース開示義務が発生
- ドキュメントが散逸している:機能が多すぎてWiki / Issues / Discordに情報が分散している
- 新機能は実験的なものが混じる:最新バージョンでは連続バッチング・MTPなどexperimentalな機能もあり、安定性に注意
動作要件
KoboldCppは「動くかどうか」のハードルは極めて低いですが、「快適に動かす」には適切なスペックが必要です。LLMサイズと用途別の目安を示します。
| 項目 | 最小(7Bモデル動作) | 標準(13B + 画像生成) | 推奨(70B + 動画生成) |
|---|---|---|---|
| OS | Windows 10 / Ubuntu 20.04 / macOS 12 | Windows 11 / Ubuntu 22.04 / macOS 14 | Windows 11 / Ubuntu 24.04 / macOS 15 |
| CPU | AVX2対応 4コア | AVX2 / AVX-512対応 8コア | 16コア以上(Ryzen 9 / Core i9 / Apple M3 Pro+) |
| GPU | 不要(CPUオンリーで動作可) | NVIDIA RTX 4060 (8GB) / Apple M2 | NVIDIA RTX 5090 / RTX 4070 Ti SUPER 複数枚 |
| VRAM | ―(CPUオンリー) | 8GB以上 | 24GB以上 or 複数GPU合計48GB+ |
| システムRAM | 16GB | 32GB | 64GB DDR5以上 |
| ストレージ | 30GB(モデル数本) | 500GB NVMe SSD | 2TB NVMe SSD(モデル+出力動画) |
| 速度目安 | 3〜8 tok/s(7B Q4) | 20〜40 tok/s(13B Q4) | 50〜120 tok/s(70B Q4) |
対応バックエンド一覧
| バックエンド | 対象GPU | 起動フラグ | 備考 |
|---|---|---|---|
| CUDA | NVIDIA GeForce / RTX / Quadro | --usecuda | 最高速度。RTX 4000 / 5000系で推奨 |
| Vulkan | NVIDIA / AMD / Intel Arc | --usevulkan | クロスベンダー対応。AMD RX 7000 / Intel Arc B580で実用 |
| Metal | Apple Silicon (M1/M2/M3/M4) | 自動検出 | macOS版バイナリで自動有効化 |
| ROCm | AMD Radeon Pro / Instinct | 非公式フォーク使用 | YellowRoseCx/koboldcpp-rocmを別途利用 |
| CLBlast | 古いGPU(OpenCL対応) | --useclblast 0 0 | レガシー用。VulkanかCUDAを優先推奨 |
| CPU only | ― | フラグ無し | 古いCPUは--noavx2を追加 |
インストール手順
KoboldCppのインストールはOSを問わず簡単ですが、それぞれの環境で最適な手順が異なります。コピペで完了する手順を示します。
Windows(推奨:CUDA版バイナリ)
NVIDIA GPUを使う場合はCUDA版バイナリ、それ以外は通常版(Vulkan対応)を選択します。
# PowerShellを管理者権限で開く
# 作業ディレクトリを作成
mkdir C:\KoboldCpp
cd C:\KoboldCpp
# 最新版バイナリをダウンロード(CUDA版)
Invoke-WebRequest -Uri "https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp.exe" -OutFile "koboldcpp.exe"
# 起動確認(GUIランチャーが立ち上がる)
.\koboldcpp.exe
# CUI起動の場合(モデルパス指定)
.\koboldcpp.exe --model C:\Models\llama-3-8b-instruct.Q4_K_M.gguf --usecuda --gpulayers 99 --contextsize 8192NVIDIA GPUを持たないPCではkoboldcpp_nocuda.exeをダウンロードし、Vulkanまたは--useclblastを指定します。
# Vulkan版バイナリ(AMD / Intel GPU向け、CUDAランタイム不要で軽量)
Invoke-WebRequest -Uri "https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp_nocuda.exe" -OutFile "koboldcpp_nocuda.exe"
.\koboldcpp_nocuda.exe --model C:\Models\llama-3-8b-instruct.Q4_K_M.gguf --usevulkan --gpulayers 35Linux(Ubuntu / Debian / Arch / Fedora共通)
# 任意のディレクトリで実行
mkdir -p ~/koboldcpp && cd ~/koboldcpp
# 最新バイナリをダウンロード
wget https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp-linux-x64
# 実行権限を付与
chmod +x koboldcpp-linux-x64
# 動作確認
./koboldcpp-linux-x64 --help
# モデル指定起動
./koboldcpp-linux-x64 \
--model ~/models/llama-3-8b-instruct.Q4_K_M.gguf \
--usecuda \
--gpulayers 99 \
--contextsize 8192 \
--port 5001 \
--host 0.0.0.0CUDA版バイナリにはNVIDIAドライバ・CUDA Toolkit 12.x以上が必要です。インストール済みでない場合は、ディストリビューションのパッケージマネージャからnvidia-driver-560以上を入れてください。
macOS(Apple Silicon)
cd ~/Downloads
# Apple Silicon用バイナリ
curl -L -o koboldcpp-mac-arm64 \
https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp-mac-arm64
chmod +x koboldcpp-mac-arm64
# Gatekeeperの隔離属性を解除(初回のみ)
xattr -d com.apple.quarantine koboldcpp-mac-arm64
# 起動(Metalバックエンドが自動有効化される)
./koboldcpp-mac-arm64 \
--model ~/Models/llama-3-8b-instruct.Q4_K_M.gguf \
--gpulayers 99 \
--contextsize 8192Apple Siliconは統一メモリアーキテクチャのため、--gpulayersを最大値(99)にして全層をGPUに乗せるのが最高速度です。Intel Mac版バイナリはv1.100以降で配布停止されたため、Intel Macユーザーはソースからビルドする必要があります。
ソースからビルドする場合(上級者向け)
git clone https://github.com/LostRuins/koboldcpp.git
cd koboldcpp
# CUDA版ビルド
make LLAMA_CUDA=1 LLAMA_OPENBLAS=1 -j$(nproc)
# Vulkan版ビルド
make LLAMA_VULKAN=1 -j$(nproc)
# Python依存も含めるならrequirements.txt経由
pip install -r requirements.txt
# 起動
python koboldcpp.py --model ~/models/llama-3-8b-instruct.Q4_K_M.gguf
初期設定
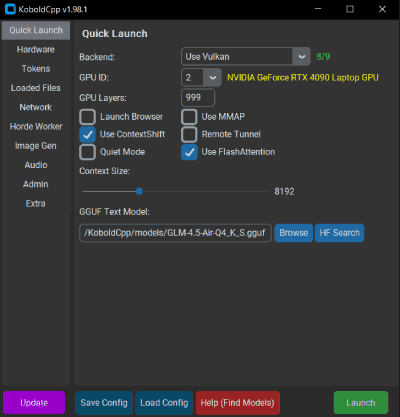
初回起動時はGUIランチャー(koboldcpp.exeをダブルクリックすると現れるウィンドウ)から設定するのが最も簡単です。CUIで全部済ませたい場合は--helpで全オプションを確認してください。
GUIランチャーから設定する
- Modelタブ:「Browse」ボタンで
.ggufファイルを指定。「Model」フィールドにファイルパスが入る - Quick Launchタブ:「Use CUDA」「Use Vulkan」など、自分のGPUに合うバックエンドにチェック
- GPU Layers:スライダーで「99」(全層オフロード)に設定。VRAM不足でクラッシュする場合は少しずつ下げる
- Context Size:8192(標準)または16384(広いコンテキスト用)
- Launchボタンを押下。コンソールに「Please connect to
http://localhost:5001」と表示されたら成功
ブラウザでKoboldAI Liteを開く
ブラウザでhttp://localhost:5001/を開くと、KoboldAI Lite UIが表示されます。右上の「Settings」アイコンから以下を設定するのが基本です。
- Settings → Format:使用モデルのプロンプトテンプレート(Llama 3 / Mistral / Gemma / ChatML 等)を選択
- Settings → Samplers:Temperature 0.7、Top-P 0.92、Min-P 0.05 が多くのモデルで無難な初期値
- Settings → Token Settings:Max Output(生成最大トークン数)を512〜2048に設定
- Settings → Memory:会話の記憶(永続コンテキスト)を入力する欄
日本語化について
KoboldAI Lite UI自体は英語のみですが、出力言語は使用するモデル次第です。日本語で会話したい場合は、日本語に強いモデルを選択してください(後述「おすすめモデル」参照)。UIメニューだけ日本語化したい場合はブラウザ翻訳機能の利用が現実的です。
基本的な使い方
チャットモード(Instruct Mode)でAIと会話する
もっとも使う頻度の高いモードです。左上のメニューから「Instruct Mode」を選択し、下部の入力欄にメッセージを入れて送信します。
User: 日本の首都はどこですか?
AI: 日本の首都は東京です。約1,400万人の人口を擁し、政治・経済・文化の中心地となっています。物語生成モード(Story Mode)
長編小説の続きを生成する用途に最適化されたモードです。「Story Mode」を選択すると、入力枠が大きくなり、続きを書かせる感覚で進められます。プロット指示はMemory欄、世界観設定はAuthor’s Note欄に分けて入れると、長文生成時に一貫性が保たれます。
アドベンチャーモード(Adventure Mode)
テキストアドベンチャーゲーム風に「あなたは~する」「言う」コマンドで進行できるモードです。KoboldAI Liteの伝統的なゲームモードです。
OpenAI互換APIで使う
KoboldCppはOpenAI互換のChat Completions APIを提供します。OpenAI Python SDKからそのまま叩けます。
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:5001/v1",
api_key="dummy" # 認証は不要だが何か入れる必要がある
)
response = client.chat.completions.create(
model="koboldcpp",
messages=[
{"role": "system", "content": "あなたは親切な日本語アシスタントです。"},
{"role": "user", "content": "PythonでフィボナッチをDP実装してください。"}
],
temperature=0.7,
max_tokens=1024,
stream=True
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)Anthropic互換APIで使う(v1.115以降)
v1.115.2ではPOST /v1/messagesがClaude API完全互換となり、Anthropic SDKからも接続できます。Claude Code・Cline・Continueなどのクライアントからローカルモデルを使う際に便利です。
import anthropic
client = anthropic.Anthropic(
base_url="http://localhost:5001",
api_key="dummy"
)
message = client.messages.create(
model="koboldcpp",
max_tokens=1024,
messages=[
{"role": "user", "content": "こんにちは、自己紹介してください。"}
]
)
print(message.content[0].text)実践的な使い方
ユースケース1:Stable Diffusion(FLUX)で画像生成
KoboldCppは画像生成専用のSDUIタブを内蔵しています。LLMモデルを起動するときに--sdmodelオプションでSDモデルを同時にロードしておくと、ブラウザ画面右側の「SDUI」タブから画像生成できます。
# LLM + FLUX.1-dev を同時ロード
./koboldcpp.exe \
--model C:\Models\llama-3-8b-instruct.Q4_K_M.gguf \
--sdmodel C:\Models\flux1-dev-Q4_0.gguf \
--sdvae C:\Models\ae.safetensors \
--sdclipt5 C:\Models\t5xxl_fp16.safetensors \
--sdclipl C:\Models\clip_l.safetensors \
--usecuda --gpulayers 99 --contextsize 8192FLUXは高品質ですがVRAMを大量に使用するため、VRAM 12GB以上推奨です。VRAMが少ない環境ではSDXLまたはSD1.5を選んでください。
ユースケース2:Whisperで音声をテキスト化
Whisperモデルを--whispermodelオプションで指定して起動すると、Web UIに音声アップロード機能が追加されます。日本語音声の場合はggml-large-v3-turbo-q8_0.binが最も精度と速度のバランスが良い選択です。
./koboldcpp.exe \
--model C:\Models\llama-3-8b-instruct.Q4_K_M.gguf \
--whispermodel C:\Models\ggml-large-v3-turbo-q8_0.bin \
--usecuda --gpulayers 99APIエンドポイント/v1/audio/transcriptionsはOpenAI Whisper API互換なので、既存のWhisperクライアントから接続できます。
ユースケース3:Qwen3 TTSで音声合成
v1.110以降、Qwen3 TTSによる音声クローン機能が標準搭載されました。--ttsmodelでTTSモデル、--ttswavtokenizerでwavtokenizerを指定して起動します。
./koboldcpp.exe \
--model C:\Models\llama-3-8b-instruct.Q4_K_M.gguf \
--ttsmodel C:\Models\Qwen3-0.6B-TTS-Q4_0.gguf \
--ttswavtokenizer C:\Models\wavtokenizer.gguf \
--usecuda --gpulayers 99API経由ではPOST /v1/audio/speech(OpenAI TTS互換)が使えます。
ユースケース4:LTX2.3で動画生成
v1.114.1で追加されたLTX2.3対応により、テキストから動画生成・画像から動画生成・動画から動画生成が可能になりました。VRAM 16GB以上が現実的な動作要件です。
./koboldcpp.exe \
--sdmodel C:\Models\ltx-video-2.3-Q5_K_M.gguf \
--sdvae C:\Models\ltx-video-vae.safetensors \
--usecuda --gpulayers 99SDUIタブで「Video」モードに切り替えると、フレーム数・FPS・カメラモーションを指定して生成できます。v1.115.2では2枚のリファレンス画像で「開始フレーム+終了フレーム」を指定できるようになり、スムーズなトランジション動画が可能になりました。
応用・カスタマイズ
RPCバックエンドで複数台のGPUを分散利用する
v1.114.1で導入されたRPCバックエンドは、複数のマシンに分散したGPUを束ねて1つの巨大モデルを動かす機能です。70B以上の巨大モデルを家庭内LANで分散推論できます。
# ワーカー側(GPUを提供するマシン)
./koboldcpp-linux-x64 --rpcserver 0.0.0.0:50052 --usecuda
# メイン側(オーケストレーションするマシン)
./koboldcpp-linux-x64 \
--model llama-3-70b-instruct.Q4_K_M.gguf \
--rpc 192.168.1.10:50052,192.168.1.11:50052 \
--usecuda --gpulayers 99OpenAI互換ルーターモード(モデル自動ホットスワップ)
v1.110で追加されたルーターモードは、複数のモデルを事前に定義しておき、APIリクエストのmodelパラメータに応じて自動的にホットスワップする機能です。
./koboldcpp.exe --modelrouter routes.json
# routes.json の例
{
"models": {
"small": {"model": "C:\\Models\\llama-3-3b.Q4_K_M.gguf", "gpulayers": 99},
"medium": {"model": "C:\\Models\\llama-3-8b.Q4_K_M.gguf", "gpulayers": 99},
"large": {"model": "C:\\Models\\llama-3-70b.Q4_K_M.gguf", "gpulayers": 40}
}
}MTP(Multi-Token Prediction)で推論を高速化
対応モデル(Gemma 4 Assistant / DeepSeek V3等)では、MTPによってスループットが大きく向上します。
./koboldcpp.exe \
--model gemma-4-26B-A4B-it-UD-Q4_K_M.gguf \
--draftmodel gemma-4-26b-A4B-it-assistant-Q4_0.gguf \
--usemtp \
--usecuda --gpulayers 99 \
--debugmode--debugmodeでドラフトモデルのhit率(投機的デコーディングの成功率)を確認できます。サンプルプロンプト「Give me the first 100 integers」では90%超のhit率が出ることが報告されています。
ローラ(LoRA)アダプタを動的に切り替える
v1.113.2でランタイム LoRA ディレクトリ切替が追加され、起動後にLoRAを動的に着脱できるようになりました。
./koboldcpp.exe \
--model llama-3-8b.Q4_K_M.gguf \
--loradir C:\Models\loras\ \
--usecuda --gpulayers 99SDUIタブのLoRAセレクタから、指定ディレクトリ内のLoRAファイルをリアルタイムで適用・解除できます。
tool_calls(ツール呼び出し)でエージェント化
v1.112.2でJinjaツール呼び出しのストリーミング対応が追加され、OpenAI / Anthropic互換APIからtoolsパラメータを使った関数呼び出しが利用できます。LangChain・LlamaIndex・OpenAI Agents SDKなどのエージェントフレームワークからそのまま使えます。
パフォーマンス最適化
量子化形式の選び方
| 量子化 | サイズ(7Bモデル) | 品質 | 速度 | 用途 |
|---|---|---|---|---|
| Q8_0 | 約7.2GB | ★★★★★ | ★★☆☆☆ | 研究用・最高品質要求 |
| Q6_K | 約5.5GB | ★★★★★ | ★★★☆☆ | VRAM 8GBで実用品質 |
| Q5_K_M | 約4.8GB | ★★★★☆ | ★★★★☆ | バランス型・推奨 |
| Q4_K_M | 約4.1GB | ★★★★☆ | ★★★★★ | 標準・もっとも普及 |
| IQ4_XS | 約3.6GB | ★★★☆☆ | ★★★★★ | VRAM 6GB向け |
| Q3_K_M | 約3.3GB | ★★☆☆☆ | ★★★★★ | 低VRAM緊急用 |
迷ったらまずQ4_K_Mを選びます。VRAMに余裕があればQ5_K_M、極限まで品質を上げたいならQ6_Kです。Q3以下は明らかな精度劣化が出るため、緊急時のみ使用してください。
KVキャッシュ量子化でコンテキストサイズを増やす
v1.112.2でq5_1 KVキャッシュ量子化が追加され、長文コンテキスト時のVRAM使用量を大幅に削減できます。
# KVキャッシュをq8_0で量子化(VRAM約半減)
./koboldcpp.exe \
--model llama-3-8b.Q4_K_M.gguf \
--quantkv 2 \
--contextsize 32768 \
--usecuda --gpulayers 99
# 値: 0=f16(デフォルト), 1=q8_0, 2=q5_1, 3=q5_0, 4=q4_1, 5=q4_0q8_0なら品質劣化はほぼなく、q5_1でもチャット用途では実用範囲です。32K以上のコンテキストを扱う場合はほぼ必須テクニックです。
Flash Attentionで高速化
NVIDIA Ampere(RTX 3000系)以降のGPUでは、Flash Attentionを有効化すると20〜30%高速化します。
./koboldcpp.exe \
--model llama-3-8b.Q4_K_M.gguf \
--flashattention \
--usecuda --gpulayers 99バッチサイズ調整で長文生成を高速化
初回プロンプト処理(プロンプトプロセシング)が遅い場合は、--blasbatchsizeを大きくします。逆にVRAMが足りない場合は小さくします。
# プロンプト処理を高速化(VRAM豊富な場合)
--blasbatchsize 2048
# VRAM節約(古いGPU)
--blasbatchsize 128連続バッチング(実験的)
v1.114.1で追加された連続バッチングは、同時並行で複数リクエストを処理する機能です。マルチユーザーAPI用途で大きな効果があります。
./koboldcpp.exe \
--model llama-3-8b.Q4_K_M.gguf \
--multiuser 4 \
--parallelizetext \
--usecuda --gpulayers 99よくあるエラーとトラブルシューティング
エラー1:起動直後にクラッシュ(古いCPU)
症状:起動した瞬間に「Illegal instruction」やWindowsのクラッシュダイアログ。
原因:CPUがAVX2に対応していない(Sandy Bridge以前など)。
対処:--noavx2または--failsafeフラグを付けて起動します。
./koboldcpp.exe --model llama-3-8b.Q4_K_M.gguf --noavx2エラー2:CUDA out of memory
症状:「CUDA error: out of memory」でモデルロード失敗。
原因:GPU層数(--gpulayers)が多すぎる、コンテキストサイズが大きすぎる。
対処:
--gpulayersの数値を減らす(99 → 30 → 20 のように段階的に)--contextsizeを縮小する(8192 → 4096)--quantkv 2でKVキャッシュを量子化する- より小さい量子化(Q4_K_M → IQ4_XS)に変更
エラー3:ポート競合(Address already in use)
症状:「Address already in use」で起動失敗。
原因:他のプロセスがポート5001を使用している(前回のKoboldCppがゾンビ化など)。
対処:別ポートを指定するか、既存プロセスを終了します。
# 別ポート使用
.\koboldcpp.exe --port 5002
# Windowsで占有プロセスを確認
netstat -ano | findstr :5001
# 表示されたPIDを終了
taskkill /F /PID PID番号エラー4:モデルロードが極端に遅い
症状:起動からチャット可能になるまで数分かかる。
原因:HDD上にモデルを置いている、メモリマップロードが効いていない。
対処:
- モデルファイルをNVMe SSDに移動する(HDDの10倍以上高速)
--useswaでSliding Window Attentionを有効化- 初回起動時はOSキャッシュに乗るまでが遅い。2回目以降は高速
エラー5:APIから接続できない(外部マシンから)
症状:他のPCやLAN内サーバーからAPI接続できない。
原因:デフォルトでlocalhostのみバインドしている、ファイアウォール。
対処:
# 全インターフェースでLISTEN
./koboldcpp.exe --host 0.0.0.0 --port 5001
# Windowsファイアウォール例外追加(PowerShell管理者)
New-NetFirewallRule -DisplayName "KoboldCpp" -Direction Inbound -Protocol TCP -LocalPort 5001 -Action Allowエラー6:日本語の応答が中国語混じりになる
症状:日本語で質問しても中国語や英語が混ざる。
原因:プロンプトテンプレートが間違っている、または英語特化モデルを使用している。
対処:
- Settings → Formatで使用モデルに合うテンプレート(Llama 3 / Qwen / Gemma等)を選択
- 日本語特化モデル(Qwen3-32B-Instruct、Llama-3-ELYZA-JP-8B、karakuri-lm-7b-chat-v0.1 等)に変更
- Temperatureを下げる(0.7 → 0.5)
エラー7:画像生成が黒画像 / ノイズだらけ
症状:SDUIで生成しても真っ黒な画像、もしくはランダムノイズが出力される。
原因:VAEが指定されていない、CFG値が極端、VRAM不足。
対処:--sdvaeでVAEファイルを明示指定、CFG Scaleを7前後に戻す、VRAMが足りなければSDXLからSD1.5に切替。
おすすめの組み合わせ・連携
SillyTavernとの連携
SillyTavernは本格的なキャラクターチャットUIです。KoboldCppをバックエンドにすると、キャラクターカード・グループチャット・世界観設定など、本格的なロールプレイ環境が構築できます。
SillyTavern側の「API Connections」で「KoboldCpp」または「Text Completion → kobold」を選択し、URLにhttp://localhost:5001を入力するだけで接続完了です。
Continue.devでVSCode内コーディングアシスタント化
VSCode拡張Continueのconfig.yamlでKoboldCppをChat / Autocompleteモデルとして登録すれば、GitHub Copilot代替として使えます。
models:
- name: KoboldCpp Llama 3
provider: openai
model: koboldcpp
apiBase: http://localhost:5001/v1
apiKey: dummy
roles:
- chat
- autocompleteOpen WebUIで複数モデルを統合管理
Open WebUIはOpenAI互換APIを叩く高機能なChatGPT風UIです。KoboldCppをバックエンドに、ベクトルDB(RAG)やWeb検索プラグインを組み合わせると、本格的なナレッジアシスタントが構築できます。
Claude Code / Clineからローカル接続
v1.115.2のAnthropic API対応により、Claude Codeのbase URLをhttp://localhost:5001に向けることで、ローカルモデルでClaude Codeのエージェント機能を使う実験が可能になりました。Claudeレベルの賢さは出ませんが、ネット遮断環境やプライバシー重視の作業では便利です。
おすすめモデル(2026年6月時点)
| モデル名 | サイズ | 用途 | 日本語 | 必要VRAM |
|---|---|---|---|---|
| Llama-3.3-70B-Instruct-Q4_K_M | 70B | 汎用最高品質 | ○ | 40GB |
| Qwen3-32B-Instruct-Q4_K_M | 32B | 多言語・コーディング | ◎ | 20GB |
| Gemma 4-26B-A4B-it-UD-Q4_K_M | 26B (MoE) | 高速+高品質 | ○ | 16GB |
| DeepSeek-V3.1-Q4_K_M | 671B (MoE) | 推論・コーディング特化 | ○ | 400GB+(CPUオフロード前提) |
| Llama-3-ELYZA-JP-8B | 8B | 日本語特化 | ◎ | 6GB |
| FLUX.1-dev-Q4_0 | ― | 画像生成 | ― | 12GB |
| SDXL-Lightning | ― | 高速画像生成 | ― | 6GB |
| ggml-large-v3-turbo-q8_0 | ― | 音声認識 | ◎ | 2GB |
モデルファイル(.gguf)はHugging Faceから「モデル名 GGUF」で検索すると見つかります。bartowski氏やunslothのリポジトリが品質高くおすすめです。
推奨PCスペック
用途別の推奨構成です。2026年6月時点のパーツ価格を踏まえて現実的な選択肢を提示します。
入門構成(13B以下のLLM+SDXL画像生成)
| パーツ | 具体例 | VRAM/容量 |
|---|---|---|
| CPU | AMD Ryzen 7 7800X3D / Intel Core i5-14600K | 8コア |
| GPU | NVIDIA RTX 4060 Ti 16GB | 16GB VRAM |
| メモリ | 32GB DDR5 5600 | 32GB |
| SSD | 1TB NVMe SSD(Gen 4) | 1TB |
| 電源 | 650W 80+ GOLD | ― |
標準構成(30B級LLM+FLUX画像生成+LTX2.3動画生成)
| パーツ | 具体例 | VRAM/容量 |
|---|---|---|
| CPU | AMD Ryzen 9 7950X / Intel Core i9-14900K | 16コア |
| GPU | NVIDIA RTX 4070 Ti SUPER 16GB | 16GB VRAM |
| メモリ | 64GB DDR5 6000 | 64GB |
| SSD | 2TB NVMe SSD(Gen 4 / Gen 5) | 2TB |
| 電源 | 850W 80+ GOLD | ― |
ハイエンド構成(70B級LLM+動画生成本格運用)
| パーツ | 具体例 | VRAM/容量 |
|---|---|---|
| CPU | AMD Ryzen Threadripper 7960X / Intel Core Ultra 9 285K | 24コア以上 |
| GPU | NVIDIA RTX 5090 32GB(または RTX 4090 24GB ×2でNVLink) | 32GB VRAM |
| メモリ | 128GB DDR5 6400 | 128GB |
| SSD | 4TB NVMe SSD(Gen 5) | 4TB |
| 電源 | 1200W 80+ PLATINUM | ― |
CPUオンリーで運用したい場合は、メモリを96GB~192GBまで増設すれば、70Bクラスでも実用速度(3〜8 tok/s)で動かせます。GPU予算が確保できない場合の選択肢として現実的です。
まとめ
KoboldCppは「1ファイル0インストール」のシンプルさを保ちつつ、LLM推論・画像生成・動画生成・音声認識・音声合成・音楽生成のすべてを1つのプロセスで完結させる、現時点で最も統合度の高いローカルAIランタイムです。2026年6月の最新版v1.115.2では、Anthropic API完全互換・Gemma 4対応・MTP・LTX2.3動画生成といった、業界の最新動向を即座に取り込んでいます。
こんな人におすすめ:
- 1台のPCでローカルAIを「全部」やりたいクリエイター
- llama.cppのビルドやPython依存に挫折した人
- OllamaのCLIだけでは物足りず、本格的なWeb UIを使いたい人
- 画像生成・動画生成までセットで運用したい人
- RPC分散でハイエンドモデルを家庭内クラスタで動かしたい人
逆に、Dockerコンテナや自社サービスへの本格組み込みでは、軽量なllama.cpp(llama-server)のほうが適しています。また、研究用途で複数バックエンドをベンチマークしたいならtext-generation-webui、純粋なチャット利用ならLM Studioと、用途に応じて使い分けるのが賢明です。
KoboldCppは更新が極めて活発で、月2回前後の頻度で新機能が追加されています。公式のリリースページとWikiを定期的にチェックして、新機能を活用していきましょう。
本記事が、あなたのローカルAI環境構築の助けになれば幸いです。
📦 この記事で紹介した商品
- 大規模言語モデル入門 → Amazonで見る
- NVIDIA GeForce RTX 4070 Ti SUPER → Amazonで見る
- Stable Diffusion画像生成ガイドブック → Amazonで見る
- Amazon | CORSAIR DDR5-5200MHz デスクトップPC用 メモリ VENGEANCE DDR5 64GB CMK64GX5M2B5… → Amazonで見る
- WD_BLACK SN7100 1TB NVMe SSD PCIe Gen4 x4 – アマゾン → Amazonで見る
※ 上記リンクはAmazonアソシエイトリンクです。購入いただくと当サイトに紹介料が入ります。
