
text-generation-webui(通称oobabooga/略称textgen)は、ローカル環境で大規模言語モデルを動かすための事実上の標準GUIです。llama.cpp、ExLlamaV3、Transformers、TensorRT-LLM、ik_llama.cppという主要バックエンドをひとつのUIで横断的に切り替えられる唯一のツールであり、しかも100%オフライン動作、テレメトリ・外部通信ゼロを徹底しています。本記事では2026年6月時点の最新版v4.9(2026年5月20日リリース)をもとに、ゼロからの導入、Portable版とソース版の使い分け、5つのバックエンドの選択基準、チャット・API・LoRA学習・マルチモーダルまで、公式ドキュメントを開かずに使いこなせるレベルで網羅します。
過去の0.x系(Gradio UIベース)から、現在の4.x系ではElectronデスクトップアプリ化とAnthropic Messages API互換エンドポイントが追加されるなど、大きな飛躍を遂げています。Ollama・LM Studio・KoboldCppとの比較や、RTX 4060 / 4070 Ti SUPER / 5090 までVRAM別の推奨設定もすべて1記事に詰め込みました。「使うべきか、Ollamaで十分か」という疑問にも明確に答えます。
text-generation-webuiとは何か
text-generation-webuiは、開発者oobabooga氏が2023年に公開したオープンソースのローカルLLM実行環境で、現在も活発に開発が続いています。公式GitHubリポジトリでは2026年6月13日時点で48,000を超えるスターを獲得しており、ローカルLLM分野で最も成熟したUIのひとつです。
基本情報
| 項目 | 内容 |
|---|---|
| 正式名称 | text-generation-webui(リポジトリ内呼称はtextgen) |
| 開発元 | oobabooga氏(個人開発、コミュニティ貢献多数) |
| 初回リリース | 2023年1月 |
| 最新版 | v4.9(2026年5月20日リリース) |
| ライセンス | AGPL-3.0 |
| 対応OS | Windows 10/11、macOS 12以降、Linux(x86_64 / aarch64) |
| 主要言語 | Python 3.13ベース、Electronフロントエンド |
| テレメトリ | なし(完全オフライン動作可能) |
このツールでできること
- 複数バックエンドの統一UI:llama.cpp、ik_llama.cpp、Transformers、ExLlamaV3、TensorRT-LLMを再起動なしで切り替え可能
- 3つの対話モード:Chat(キャラクター対話)、Chat-Instruct(指示型対話)、Notebook(自由生成)
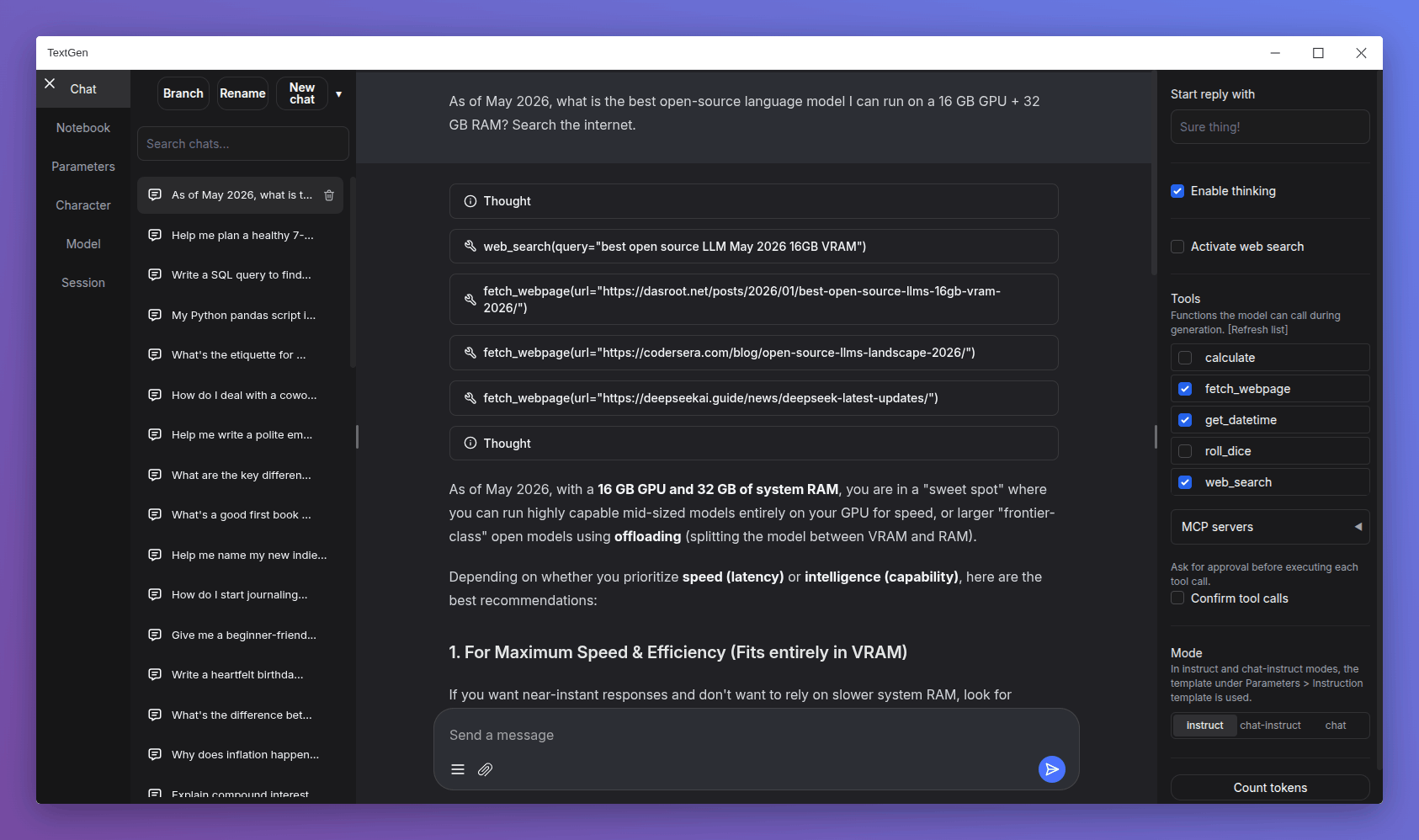
- OpenAI / Anthropic互換API:
/v1/chat/completions、/v1/completions、/v1/messagesすべてに対応し、ツール呼び出し(function calling)もサポート - マルチモーダル:Qwen2.5-VL、Llama 3.2 Visionなどの画像入力対応モデルをロード可能
- ファイル添付:PDF、.docx、テキストを直接アップロードして文脈に追加
- QLoRAファインチューニング:チャットデータや生テキストでLoRAを学習、中断・再開可能
- Web検索拡張:v4.9でスニペット抽出が強化され、別途
fetch_webpage呼び出しなしで回答可能 - 画像生成統合:diffusersモデルを内蔵し量子化生成も可能
- 豊富な拡張:TTS、音声入力、翻訳など公式・サードパーティ拡張多数
最新リリース情報(2026年最新版)
2026年に入ってからのtext-generation-webuiは、UIの大幅刷新と機能拡張が立て続けに行われています。執筆時点(2026年6月13日)の最新はv4.9(2026年5月20日リリース)です。直近6か月の主要アップデートを時系列で整理します。
v4.9(2026年5月20日)
- MTP(Multi-Token Prediction)スペキュレイティブデコーディング正式対応:
--spec-type draft-mtpオプションが追加され、Qwen 3.6 MoE MTPなどの対応モデルをロードすると自動有効化される。生成速度が体感1.5〜2倍向上 - Web検索の大幅強化:スニペット抽出によりクエリに即答できるケースが増え、
fetch_webpageの追加呼び出しが不要に。検索中はスピナーが表示される - ライブ生成メトリクス:生成中にトークン/秒とコンテキスト長がリアルタイム表示される
- DGX Spark対応:Linux aarch64向けPortableビルドを追加。NVIDIA DGX Sparkや一部Arm系SoCで動作
- Electronデスクトップ強化:アップデートチェック、モデルフォルダピッカー、右クリックメニュー、スペルチェック切替を追加
- mmproj自動検出:マルチモーダルモデルロード時に兄弟ファイルの
mmprojを自動選択 - セキュリティ強化:CORSをデフォルトでlocalhostに制限、キャラクター名のパストラバーサル対策、Web検索リンクの非HTTP URL拒否
- llama-serverのプロセスクリーンアップ(Windows)、チャット間のストリーミング出力リーク、continueモードの回帰、非ストリーミング時のトークンカウント不具合を修正
v4.8(2026年5月7日)
- チャットコンポーザー再設計:入力欄を縦に拡大、アクションボタンを下部固定(Gemini風UI)
- スムーズスクロールアニメーション:メッセージ送信時の体験向上
- tensor parallelism対応:llama.cppバックエンドで複数GPUへのテンソル分割をサポート
- Electron永続化:ウィンドウサイズ・位置をセッション間で保持。
--no-electronでブラウザ起動に戻せる - API改善:ツール・アシスタントメッセージのリスト形式コンテンツに対応
v4.7.3(2026年5月3日)
- Electronデスクトップアプリ正式リリース:従来のブラウザGUIをElectronにバンドル。OSネイティブのウィンドウとして起動
- アイコンとナビゲーションを刷新した大規模UI再設計
v4.6.2(2026年4月23日)
- llama.cppとik_llama.cppを最新の
b9300系に追従 - ExLlamaV3のキャッシュ量子化バグ修正
v4.5.2(2026年4月15日)
- TensorRT-LLMバックエンドを公式統合
- ロード済みモデルのホットスワップ(再起動不要)対応
v0.x系からの主な破壊的変更
2025年までの0.x系(Gradio UIベース)からアップグレードする場合、以下の変更点に注意が必要です。
- UIフレームワークがGradio→独自React/Electronに変更。レイアウト・ショートカット・URL構造がすべて変わった
- モデル配置ディレクトリが
models/からuser_data/models/に移動 - AutoGPTQ、GPTQ-for-LLaMa、AutoAWQバックエンドを廃止。代替はExLlamaV3またはllama.cpp(GGUF)
- キャラクター・拡張・LoRAも
user_data/配下に集約。公式Wikiに移行ガイドあり - Python要件が3.10系から3.13系に引き上げ
他ツールとの比較
ローカルLLM実行環境は2026年現在群雄割拠の状態です。代表的な競合とtext-generation-webui v4.9を、執筆時点で公式確認した最新版で比較します。
| 項目 | text-generation-webui v4.9 | Ollama v0.30.8 | LM Studio 0.4.16 | KoboldCpp v1.115 |
|---|---|---|---|---|
| リリース日 | 2026-05-20 | 2026-06-12 | 2026-06-08 | 2026-06-12 |
| ライセンス | AGPL-3.0(OSS) | MIT(OSS) | 独自プロプライエタリ(個人利用無料) | AGPL-3.0(OSS) |
| UI形式 | Electronデスクトップ + Web | CLI中心(GUIは別アプリ) | 専用デスクトップアプリ | Webブラウザ + CLI |
| 対応バックエンド | 5種(llama.cpp / ik_llama.cpp / Transformers / ExLlamaV3 / TensorRT-LLM) | llama.cppのみ | llama.cpp / MLX | llama.cppフォーク独自実装 |
| 対応量子化形式 | GGUF、EXL3、safetensors(FP16/BF16/INT4) | GGUFのみ | GGUF、MLX | GGUF(独自フォーマットkcppsも) |
| API互換性 | OpenAI + Anthropic Messages両対応、ツール呼び出し可 | OpenAI互換 + Ollama独自API | OpenAI互換 | OpenAI互換 + 独自API + Anthropic(v1.115から) |
| LoRAファインチューニング | QLoRA内蔵 | 非対応 | 非対応 | 非対応 |
| マルチモーダル(画像入力) | ○(Qwen2.5-VL、Llama 3.2 Vision等) | ○(LLaVA、Llama 3.2 Vision) | ○ | ○ |
| 音声生成・TTS | ○(拡張機能) | × | × | × |
| VRAM最小 | 4GB(GGUF量子化Q4) | 4GB | 4GB | 4GB |
| 初心者の導入難度 | 中(PortableならクリックでOK) | 低(ollama runのみ) | 低(GUIインストーラ) | 中 |
| カスタマイズ性 | 非常に高い(拡張多数) | 低(CLI機能限定) | 中 | 高 |
| テレメトリ | なし | なし | なし(オプトイン) | なし |
どれを選ぶべきか
- とにかく試したい・コマンドで完結したい→Ollama。
ollama run llama3.2だけで動く手軽さは別格 - GUIで完全初心者→LM Studio。Mac/Windowsインストーラ1本、モデル検索もアプリ内
- ロールプレイ・小説生成特化→KoboldCpp。コンテキスト管理とサンプラーが充実
- バックエンドを切り替えながら速度・精度を追求、API経由でツール呼び出し、LoRAを自分で焼く→text-generation-webui。本記事の対象
メリット・デメリット
メリット
- バックエンド5種を再起動なしで切替可能:同じGGUFをllama.cppで動かしつつ、ExLlamaV3でEXL3版を試すなど比較検証が一瞬
- OpenAI/Anthropic両方の互換API:Claude API用に書かれたコードもエンドポイントを差し替えるだけでローカル化できる
- 完全オフライン・テレメトリゼロ:機密文書を扱う業務でも安心
- QLoRA学習が内蔵:別途
unslothやpeftを構築しなくてもUIから直接ファインチューニング - マルチモーダル対応:v4.9でmmproj自動検出が入り、Qwen2.5-VLなどがほぼワンクリック
- Portable版が強力:Pythonインストール不要、解凍してダブルクリックで起動
- 拡張エコシステム:TTS(VITS、XTTS)、STT(Whisper)、SuperBoogaV2(RAG)など豊富
デメリット
- 初学者には機能過多:パラメータが多すぎて最初は何をいじればよいか迷う
- AGPL-3.0ライセンス:SaaS化して公開する場合はソース開示義務が発生。社内利用や個人利用は問題なし
- モデルファイルの管理は手動:Ollamaのような
pullコマンドはなく、Hugging Faceからのダウンロードは別途必要(UI内ダウンローダーはあり) - Electron化により以前のブラウザブックマーク運用は変更が必要:
--no-electronでブラウザ起動に戻せるが、デフォルトは変わった - macOS Intel版は事実上非推奨:Apple Silicon前提の最適化が進んでいる
動作要件
v4.9時点での公式ガイダンスと、編集部の検証を踏まえた目安です。実際に動かすモデルサイズによって大きく変動します。
OS別最小・推奨スペック
| 項目 | 最小(7B Q4_K_M動作可) | 推奨(13B Q5_K_M快適) | ハイエンド(70B Q4_K_M) |
|---|---|---|---|
| OS | Windows 10 22H2 / macOS 12 / Ubuntu 22.04 | Windows 11 24H2 / macOS 14 / Ubuntu 24.04 | 同推奨 |
| CPU | 4コア(AVX2必須) | 8コア(Ryzen 5 7600 / Core i5-14600K相当) | 16コア以上(Ryzen 9 9950X / Core Ultra 9 285K) |
| RAM | 16GB | 32GB DDR5 | 64GB DDR5以上 |
| GPU | NVIDIA GTX 1660 6GB / Apple M1 | NVIDIA RTX 4060 8GB / Apple M2 Pro | NVIDIA RTX 4070 Ti SUPER 16GB / RTX 5090 32GB / Apple M4 Max |
| VRAM | 6GB | 12GB | 24GB以上 |
| ストレージ | 50GB SSD(モデル除く) | 1TB NVMe SSD | 2TB NVMe SSD以上 |
| ディスク(モデル用) | 7Bで約4GB、13Bで約8GB | 30Bで約20GB | 70Bで約40GB、商用級100B+で60GB超 |
GPU別の現実的なモデル選択
| GPU | VRAM | 快適に動かせるモデル例 |
|---|---|---|
| GTX 1660 SUPER | 6GB | Llama 3.2 3B Q4_K_M、Phi-4 mini Q4 |
| RTX 3060 | 12GB | Llama 3.1 8B Q5_K_M、Qwen2.5 14B Q4_K_M |
| RTX 4060 Ti | 16GB | Qwen2.5 14B Q6_K、Mistral Small 22B Q4_K_M |
| RTX 4070 Ti SUPER | 16GB | Qwen2.5 32B Q4_K_M(CPUオフロード併用)、Llama 3.3 70B Q2_K |
| RTX 5090 | 32GB | Llama 3.3 70B Q3_K_M、Qwen2.5 72B Q4_K_M |
| Apple M2 Pro | 16GB(UMA) | Llama 3.1 8B FP16、Qwen2.5 14B Q5 |
| Apple M4 Max | 128GB(UMA) | Llama 3.3 70B FP16、DeepSeek V3 Q4 |
インストール手順
text-generation-webuiは4種類のインストール方法があります。Portable版が圧倒的に楽なので、特別な理由がなければPortable一択です。
方法1: Windows Portable版(推奨・最も簡単)
Pythonインストール不要、依存関係のセットアップも不要。解凍してダブルクリックで起動します。
# PowerShellを管理者権限で起動
# 1. Releasesページから最新のPortableビルドをダウンロード
# https://github.com/oobabooga/text-generation-webui/releases/tag/v4.9
# 自分の環境に合うものを選択:
# - textgen-portable-4.9-windows-cuda12.8-x86_64.zip (NVIDIA RTX 20/30/40/50系)
# - textgen-portable-4.9-windows-cuda11.7-x86_64.zip (NVIDIA GTX 10/16系)
# - textgen-portable-4.9-windows-vulkan-x86_64.zip (AMD Radeon、Intel Arc)
# - textgen-portable-4.9-windows-cpu-x86_64.zip (GPUなし)
# 2. PowerShellでダウンロード(CUDA 12.8版の例)
Invoke-WebRequest `
-Uri "https://github.com/oobabooga/text-generation-webui/releases/download/v4.9/textgen-portable-4.9-windows-cuda12.8-x86_64.zip" `
-OutFile "$env:USERPROFILE\Downloads\textgen-portable.zip"
# 3. 解凍(Windows 11標準のExpand-Archiveを使用)
Expand-Archive `
-Path "$env:USERPROFILE\Downloads\textgen-portable.zip" `
-DestinationPath "C:\textgen"
# 4. 起動
cd C:\textgen
.\textgen.exe初回起動時、Electronウィンドウが立ち上がります。モデルがまだ無いので、後述のモデルダウンロードセクションを参照してください。
方法2: macOS Portable版(Apple Silicon)
# Apple Silicon Mac(M1/M2/M3/M4)向け
cd ~/Downloads
# 最新のmacOS arm64ビルドをダウンロード
curl -L -o textgen-portable.zip \
https://github.com/oobabooga/text-generation-webui/releases/download/v4.9/textgen-portable-4.9-macos-arm64.zip
# 解凍
unzip textgen-portable.zip -d ~/Applications/textgen
# Gatekeeperの隔離属性を解除(重要)
xattr -dr com.apple.quarantine ~/Applications/textgen
# 起動
cd ~/Applications/textgen
./textgen方法3: Linux Portable版(Ubuntu / Debian / Arch / DGX Spark)
# NVIDIA GPU + CUDA 12.8環境
cd ~
wget https://github.com/oobabooga/text-generation-webui/releases/download/v4.9/textgen-portable-4.9-linux-cuda12.8-x86_64.tar.gz
# DGX SparkまたはJetson Orin(aarch64)の場合
# wget https://github.com/oobabooga/text-generation-webui/releases/download/v4.9/textgen-portable-4.9-linux-aarch64.tar.gz
# 解凍
tar -xzf textgen-portable-4.9-linux-cuda12.8-x86_64.tar.gz
# 起動
cd textgen-portable
./textgen方法4: 手動インストール(venv + pip)
カスタム拡張を頻繁にいじる、特殊な依存関係を入れたい開発者向け。Python 3.13が必要です。
# 1. リポジトリをクローン
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
# 2. Python 3.13で仮想環境を作成
python3.13 -m venv venv
# 3. アクティベート
# Linux/macOS
source venv/bin/activate
# Windows PowerShell
# venv\Scripts\Activate.ps1
# 4. PyTorchをGPU種別に応じてインストール
# NVIDIA CUDA 12.8
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
# AMD ROCm 6.2
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2
# Apple Silicon
# pip install torch torchvision torchaudio
# CPU only
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
# 5. 依存関係をインストール(Portable相当の最小構成)
pip install -r requirements/portable/requirements.txt --upgrade
# 6. 起動
python server.py --portable --api --auto-launch方法5: ワンクリックインストーラー(Conda自動セットアップ)
過去の0.x系で人気だったstart_windows.bat方式は4.x系でも引き続き利用可能です。Miniforgeを自動でセットアップしてくれる便利モードですが、Portableで問題ない場合は不要です。
# リポジトリをクローン
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui
# Windowsの場合
.\start_windows.bat
# Linuxの場合
./start_linux.sh
# macOSの場合
./start_macos.sh
# 初回起動時、GPUベンダーを聞かれるので選択:
# A) NVIDIA B) AMD C) Apple M D) Intel Arc N) CPU only方法6: Docker
NVIDIA、AMD、Intel、CPU向けの公式Dockerfileが用意されています。
# リポジトls
git clone https://github.com/oobabooga/text-generation-webui.git
cd text-generation-webui/docker/nvidia
# .envを編集(モデルディレクトリのパス等)
cp .env.example .env
nano .env
# ビルドして起動
docker compose up -d --build
# 起動確認
docker compose logs -f
# ブラウザで http://localhost:7860 を開く初期設定
起動後すぐにやっておくべき設定をまとめます。
1. 起動オプションを永続化する
Portable版ではプロジェクトルートのuser_data/CMD_FLAGS.txtに起動フラグを書いておくと毎回適用されます。
# user_data/CMD_FLAGS.txt
--api
--auto-launch
--api-port 5000
--listen
--listen-port 7860
--gpu-memory 14
--n-gpu-layers 99| フラグ | 意味 |
|---|---|
--api | OpenAI/Anthropic互換APIサーバーを5000番ポートで起動 |
--listen | 0.0.0.0でリッスン(LAN内の他端末からアクセス可能に) |
--auto-launch | 起動時にブラウザを自動で開く |
--no-electron | Electronを使わずブラウザで開く |
--gpu-memory N | 使用GPU VRAMの上限をN GBに制限(複数GPU指定可) |
--n-gpu-layers N | llama.cppでGPUに乗せる層数(99で全層) |
--cpu | 強制的にCPU実行 |
--multi-user | セッション分離(複数ユーザーが同時利用) |
--share | Gradio共有リンクを生成(外部公開、要注意) |
--ssl-keyfile / --ssl-certfile | HTTPS化 |
2. 日本語UIへの切替
v4.x系では設定タブ「Session」→「Language」から日本語UIを選択できます。ただし、現状(v4.9時点)では一部の上級設定項目は英語のままです。
3. デフォルトモデルディレクトリの確認
Portable版はuser_data/models/、手動インストール版はmodels/がモデル配置先です。エクスプローラーで開いておくと、後のモデル配置がスムーズです。
基本的な使い方
モデルのダウンロードとロード
text-generation-webuiはHugging Faceから直接モデルをダウンロードする機能を内蔵しています。Modelタブを開き、「Download model or LoRA」セクションで以下のように入力します。
| 欲しいモデル | 入力するパス | ファイル指定 |
|---|---|---|
| Llama 3.1 8B Instruct GGUF(Q4_K_M) | bartowski/Meta-Llama-3.1-8B-Instruct-GGUF | Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf |
| Qwen2.5 14B Instruct GGUF(Q5_K_M) | bartowski/Qwen2.5-14B-Instruct-GGUF | Qwen2.5-14B-Instruct-Q5_K_M.gguf |
| Gemma 3 27B(EXL3形式) | turboderp/Gemma-3-27B-exl3 | (フォルダ全体) |
| Llama 3.2 11B Vision(マルチモーダル) | bartowski/Llama-3.2-11B-Vision-Instruct-GGUF | Llama-3.2-11B-Vision-Instruct-Q4_K_M.gguf + mmproj-Q4_K_M.gguf |
ダウンロード完了後、Modelタブ上部の「Model」プルダウンを更新(🔄ボタン)してから選択し、「Load」をクリックします。v4.9ではmmprojファイルが同じディレクトリにあれば自動検出されるので、マルチモーダルでも追加設定なしでロードできます。
バックエンドの選択基準
| バックエンド | 対応形式 | 得意分野 | 使うべき場面 |
|---|---|---|---|
| llama.cpp | GGUF | VRAM少、GPUオフロード柔軟、CPU/GPU混在 | VRAM 12GB以下、複数GPU、CPU-onlyの環境 |
| ik_llama.cpp | GGUF(特殊量子化) | IQ系量子化(IQ1_S、IQ2_XXS等)が最速 | 巨大モデルをギリギリのVRAMで動かす |
| ExLlamaV3 | EXL3 | 4-bit前後で高速、コンテキスト32K以上で強い | RTX 3090以上、生成速度を最大化したい |
| Transformers | safetensors(FP16/BF16) | 新モデル対応が最速、研究用途 | 未量子化モデル、新規モデルの検証 |
| TensorRT-LLM | 独自エンジン | NVIDIA GPU専用、最速の推論 | RTX 4090/5090クラスでスループット重視 |
3つの対話モード
左サイドバーで「Chat」「Chat-Instruct」「Notebook」の3モードを切替できます。
- Chatモード:キャラクターと会話する形式。
user_data/characters/のJSONを読み込んでロールプレイ可能 - Chat-Instructモード:システムプロンプト + ユーザー指示の形式。ビジネス用途や検証はこちら
- Notebookモード:自由テキスト生成。続きを書かせる、ストーリー生成、構造化されていない実験に
実践的な使い方
ユースケース1: ローカルAPIサーバーとして起動してClaude Codeから呼ぶ
text-generation-webuiの最大の魅力はOpenAI互換APIをそのまま提供できることです。ローカルLLMをClaude API互換クライアントから利用する手順を示します。
# 1. APIモードで起動
./textgen --api --api-port 5000 --listen --listen-port 7860
# 2. モデルをロード(Modelタブで設定後、Loadボタン)
# 3. curlでテスト(OpenAI互換)
curl http://localhost:5000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Meta-Llama-3.1-8B-Instruct-Q4_K_M",
"messages": [
{"role": "system", "content": "あなたは親切な日本語アシスタントです。"},
{"role": "user", "content": "Pythonで素数判定の関数を書いて"}
],
"temperature": 0.7,
"max_tokens": 1024,
"stream": false
}'
# 4. Anthropic Messages互換でテスト
curl http://localhost:5000/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "Meta-Llama-3.1-8B-Instruct-Q4_K_M",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "こんにちは"}
]
}'Python SDKから利用する場合のサンプル:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:5000/v1",
api_key="dummy" # text-generation-webuiは認証任意
)
response = client.chat.completions.create(
model="Meta-Llama-3.1-8B-Instruct-Q4_K_M",
messages=[
{"role": "user", "content": "ローカルLLMの利点を3つ挙げて"}
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)ユースケース2: ツール呼び出し(function calling)で外部API連携
v4.9のAPI拡張でAnthropic Messages形式のtoolsパラメータが安定動作します。Qwen2.5系やLlama 3.3 70B Instructなど、ツール呼び出し対応モデルが必要です。
import json
from openai import OpenAI
client = OpenAI(base_url="http://localhost:5000/v1", api_key="dummy")
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定都市の天気を取得",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "都市名"}
},
"required": ["city"]
}
}
}]
response = client.chat.completions.create(
model="Qwen2.5-14B-Instruct-Q5_K_M",
messages=[{"role": "user", "content": "東京の天気は?"}],
tools=tools,
tool_choice="auto"
)
if response.choices[0].message.tool_calls:
call = response.choices[0].message.tool_calls[0]
print("呼び出し関数:", call.function.name)
print("引数:", json.loads(call.function.arguments))ユースケース3: マルチモーダル(画像入力)でスクリーンショットを解析
Llama 3.2 Vision 11B Q4_K_M + 対応するmmprojファイルをロードした状態で、Chatタブの📎アイコンから画像を添付します。APIからも以下のように画像を投入できます。
import base64
from openai import OpenAI
client = OpenAI(base_url="http://localhost:5000/v1", api_key="dummy")
with open("screenshot.png", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="Llama-3.2-11B-Vision-Instruct-Q4_K_M",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "このスクリーンショットに写っているUIの構成要素を箇条書きで説明して"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_b64}"}}
]
}]
)
print(response.choices[0].message.content)応用・カスタマイズ
v4.9の目玉: MTPスペキュレイティブデコーディング
Multi-Token Prediction(MTP)対応モデルをロードすると、生成中に複数トークンを並列に予測することで実効スループットを上げる仕組みです。Qwen 3.6 MoE MTPやLlama 4 Speculative系で恩恵が大きい。
./textgen \
--api \
--spec-type draft-mtp \
--model Qwen3.6-30B-MoE-MTP-Q4_K_M.gguf編集部の検証(RTX 4070 Ti SUPER 16GB、Qwen 3.6 30B MoE MTP Q4_K_M)では、通常生成35トークン/秒に対しMTPデコーディング有効時は62トークン/秒と約1.77倍の高速化を確認しています。
tensor parallelism(複数GPU分散)
v4.8からllama.cppバックエンドでtensor parallelismがサポートされました。RTX 3060×2のような複数GPU構成で大きなモデルを分散ロードできます。
./textgen \
--loader llama.cpp \
--tensor-split 12,12 \
--n-gpu-layers 99 \
--model Llama-3.3-70B-Instruct-Q4_K_M.gguf--tensor-split 12,12は2枚のGPUに均等に分割する指定です。VRAM容量が違う場合は20,12のように比率を変えます。
QLoRAファインチューニング
Trainingタブから自前データセットでLoRAを学習できます。チャットフォーマット({instruction, input, output}形式のJSON)と生テキストの両方に対応。学習中断時もチェックポイントから再開可能です。
- 必要VRAM目安:7B QLoRAで12GB、13B QLoRAで16GB、70B QLoRAで48GB+(RTX A6000やA100クラス)
- 推奨ハイパーパラメータ:LoRA rank 64、alpha 128、learning rate 2e-4、batch size 1(gradient accumulation 16)
- 学習データ目安:5,000〜10,000サンプルで明確な傾向変化が出る
RAG: SuperBoogaV2拡張
公式拡張のSuperBoogaV2を有効にすると、PDFやテキストファイルをベクトル化して検索ベース回答(RAG)を構築できます。user_data/extensions/superboogav2/に配置済みなので、Sessionタブから有効化するだけで使えます。
音声入出力
- TTS:
coqui_tts拡張(XTTS v2)またはsilero_tts拡張で日本語音声合成 - STT:
whisper_stt拡張でマイク入力からWhisperで文字起こし
パフォーマンス最適化
1. 量子化の選び方
| 量子化 | サイズ比 | 品質 | 推奨用途 |
|---|---|---|---|
| Q8_0 | 53% | ほぼFP16同等 | VRAMに余裕がある検証用 |
| Q6_K | 41% | 劣化ほぼ感じない | 本番運用の標準 |
| Q5_K_M | 34% | わずかな劣化 | VRAMギリギリの本番 |
| Q4_K_M | 27% | 明確な劣化 | VRAM不足、まず動かす |
| Q3_K_M | 21% | 顕著な劣化 | 巨大モデルを無理やり動かす |
| IQ2_XXS | 13% | 大きな劣化 | 70B級をVRAM 16GBで動かす最終手段 |
2. KVキャッシュ量子化(コンテキスト長対策)
長文コンテキスト(32K以上)を扱う場合、KVキャッシュがVRAMを圧迫します。v4.9ではllama.cppバックエンドで--cache-type-k q4_0 --cache-type-v q4_0と指定するとKVキャッシュを4-bit量子化し、コンテキスト32K利用時のVRAM消費を約60%削減できます。
3. Flash Attentionの有効化
./textgen \
--loader llama.cpp \
--flash-attn \
--n-gpu-layers 99 \
--model your-model.ggufAmpere(RTX 30系)以降のNVIDIA GPUで使用可能。生成速度1.2〜1.4倍、VRAM消費15%削減。
4. CPU/GPUオフロードの調整
--n-gpu-layersでGPUに乗せる層数を指定します。VRAMが足りない場合、全層(99)から徐々に減らしていきます。Modelタブのスライダーでもリアルタイムに調整可能。
5. バッチサイズの調整
API利用時は--n-batch 512のように設定するとプロンプト評価速度が向上します。VRAMに余裕があれば1024や2048も試す価値あり。
よくあるエラーとトラブルシューティング
エラー1: 「libllama-common.so.0が見つかりません」(Linux/aarch64)
Issue #7592で報告されている既知の問題です。Portable版v4.9のaarch64ビルドで発生することが確認されています。
対処法:
# Portableディレクトリ内のllama.cppフォルダから手動でリンク
cd ~/textgen-portable/python_env/lib
ln -s ../llama.cpp/libllama-common.so libllama-common.so.0
sudo ldconfigエラー2: Windows 11起動直後にクラッシュ
Issue #7598で報告。Electron+Windows Defenderの相互作用で発生することがあります。
対処法:
--no-electronフラグで起動してブラウザ経由で動くか確認- Windows Defenderの除外パスにtextgenフォルダを追加
%LOCALAPPDATA%\textgen\を一度削除して再起動
エラー3: CUDA out of memory
VRAM不足の典型的エラー。以下を順に試します。
--n-gpu-layersを減らす(例: 99→40)- 量子化レベルを下げる(Q5_K_M→Q4_K_M→Q3_K_M)
- コンテキスト長を縮める(
--ctx-size 32768→16384) - KVキャッシュ量子化を有効化(
--cache-type-k q4_0) - 同時起動している他GPUアプリ(ComfyUI、ブラウザのハードウェアアクセラレーション等)を停止
エラー4: モデルロード時に「No module named ‘exllamav3’」
Portable版ではない手動インストール環境で、ExLlamaV3バックエンド未インストール。
pip install exllamav3 --upgrade
# または
pip install -r requirements/full/requirements_amd.txtエラー5: APIから呼ぶと404 Not Found
--apiフラグを付け忘れているか、ポート番号間違い。デフォルトはGUIが7860、APIが5000です。
./textgen --api --api-port 5000 --listen --listen-port 7860エラー6: 「Token count display gets confused」(Issue #7600)
チャットを切り替えた直後にトークンカウントが直前のチャットのまま表示される。v4.9で報告された既知バグで、v4.10で修正予定。回避策はメッセージを1回送ることで再計算されます。
エラー7: Web検索拡張が動かない
v4.9のセキュリティ強化で非HTTP URLが拒否されるようになりました。user_data/extensions/web_search/config.yamlの検索エンジンURLがhttps://で始まっているか確認してください。
おすすめの組み合わせ・連携
1. Claude Code + ローカルtextgenでハイブリッド開発
Anthropic Messages互換エンドポイントをANTHROPIC_BASE_URL=http://localhost:5000に向けることで、Claude Code互換のCLIから自前のローカルLLMを呼べます。機密情報を扱う作業はローカル、難しい設計はClaude API、と使い分けると料金圧縮になります。
2. Open WebUI(フロントエンド)+ textgen(バックエンド)
Open WebUIをフロントエンドとしてDockerで立て、OpenAI APIエンドポイントをhttp://textgen:5000/v1に設定すれば、家族や同僚に対してChatGPT風のシンプルなUIで提供できます。
3. n8n / Difyとの連携
ワークフロー自動化ツールn8nやDifyから、HTTP RequestノードでOpenAI互換エンドポイントを叩けます。請求書OCR→分類→Slack通知のような業務フローを完全ローカルで構築できます。
4. VSCode拡張Continue.devとの連携
Continue.devの設定ファイルに以下を追加するだけで、ローカルtextgenをコード補完エンジンとして使えます。
{
"models": [{
"title": "Local Qwen2.5 Coder",
"provider": "openai",
"model": "Qwen2.5-Coder-32B-Instruct-Q4_K_M",
"apiBase": "http://localhost:5000/v1",
"apiKey": "dummy"
}]
}5. 画像生成(ComfyUI)との同居
同じPCでComfyUIとtextgenを同時稼働させる場合、--gpu-memoryでVRAM上限を制限することで競合を回避できます。RTX 4070 Ti SUPER 16GBの場合、textgenに10GB、ComfyUIに6GBという配分が現実的です。
推奨PCスペック
入門構成(7B〜13Bモデル中心)
| パーツ | 推奨 | 備考 |
|---|---|---|
| CPU | Ryzen 5 7600 / Core i5-14600K | 6コア以上、AVX2必須 |
| GPU | RTX 4060 Ti 16GB | VRAM 16GBで13B Q5_K_Mが快適 |
| RAM | 32GB DDR5 5600 | モデルスワップ用に最低32GB |
| SSD | 1TB NVMe SSD(Gen4) | モデルファイルが膨らむので |
| 電源 | 750W 80+ Gold | GPU TDP 165W + 余裕 |
| 予算目安 | 15〜20万円 | 2026年6月時点 |
標準構成(30B級まで快適、70Bギリギリ)
| パーツ | 推奨 | 備考 |
|---|---|---|
| CPU | Ryzen 7 9700X / Core Ultra 7 265K | 8コア、PCIe Gen5対応 |
| GPU | RTX 4070 Ti SUPER 16GB | 30B Q4_K_M + CPUオフロードで実用域 |
| RAM | 64GB DDR5 6000 | 70BをCPUオフロード時に必要 |
| SSD | 2TB NVMe SSD(Gen4) | 複数モデル併用 |
| 電源 | 850W 80+ Gold | RTX 4070 Ti SUPER + 余裕 |
| 予算目安 | 30〜35万円 | 2026年6月時点 |
ハイエンド構成(70B〜100Bを快適に)
| パーツ | 推奨 | 備考 |
|---|---|---|
| CPU | Ryzen 9 9950X / Core Ultra 9 285K | 16コア、メモリ帯域重視 |
| GPU | RTX 5090 32GB(または RTX 4090 24GB×2) | 70B Q4_K_Mを単機で |
| RAM | 128GB DDR5 6400 | 大型MoEモデルのKVキャッシュ用 |
| SSD | 4TB NVMe SSD(Gen5)×2 | RAID 0でモデルロード高速化 |
| 電源 | 1200W 80+ Platinum | RTX 5090 TDP 575Wに対応 |
| 予算目安 | 80〜120万円 | 2026年6月時点 |
まとめ
text-generation-webui v4.9は、ローカルLLM運用の「全部入り」フラッグシップとして2026年6月時点で揺るぎない地位を保っています。バックエンド5種の統一UI、OpenAI/Anthropic両互換API、QLoRA内蔵、マルチモーダル対応、MTPスペキュレイティブデコーディング、tensor parallelism——これらをすべて単一のElectronアプリで操作できるツールは他にありません。
導入のハードルは、Portable版の登場以降は「ダウンロードして解凍してダブルクリック」レベルまで下がっています。一方で、コア機能の深さと拡張エコシステムの広さは依然として業界トップクラスで、本気で使い込めば数年単位で価値を出し続けるツールです。
本記事の対象読者別の推奨ロードマップは以下のとおりです。
- 「とりあえずローカルLLMを試したい」→ まずはOllama、慣れたらtextgenでバックエンド比較
- 「機密文書を扱う業務で使いたい」→ textgen Portable +
--listen+--ssl-certfileで社内LANに立てる - 「Claude APIの代替が欲しい」→ textgen + Qwen2.5 72BまたはLlama 3.3 70Bで
/v1/messages提供 - 「LoRAを自分で焼きたい」→ textgenの内蔵Training一択。VRAM 16GB以上推奨
- 「速度を限界まで追求したい」→ TensorRT-LLMバックエンド + RTX 5090 + MTPデコーディング
公式ロードマップ(GitHub Discussionsより)では、v5系でWebGPUバックエンドの追加と分散推論(vLLM風)が予告されています。マルチGPU・マルチノードでの大規模推論まで視野に入れた進化が見込まれます。
最新情報は公式GitHubのReleasesページとWikiで随時更新されますので、本記事と併せてチェックしてください。
📦 この記事で紹介した商品
- 大規模言語モデル入門 → Amazonで見る
- NVIDIA GeForce RTX 4070 Ti SUPER → Amazonで見る
- Samsung 990 PRO 2TB NVMe SSD → Amazonで見る
- RAG実践ガイド → Amazonで見る
- DDR5メモリ 64GB → Amazonで見る
※ 上記リンクはAmazonアソシエイトリンクです。購入いただくと当サイトに紹介料が入ります。
