
ComfyUIは、Stable DiffusionやFLUX、LTX-Video、Wan2.7などの最新AI生成モデルを、ノードベースのワークフローで自在に制御できる強力なオープンソースGUIです。2023年1月の公開以来、その柔軟性と高速性から世界中のAIクリエイターに支持され、2026年4月現在、最新版はv0.19.0(2026年4月13日リリース)に達しています。本記事では、ComfyUIを完全にゼロからインストールし、画像・動画を実際に生成できるようになるまでを徹底解説します。Windows・Mac・Linuxすべてのインストール手順、ノード操作の基礎、FLUXやControlNet・LoRAを使った実践ワークフロー、よくあるエラーの解決策まで、公式ドキュメントを別途読む必要がない決定版ガイドを目指しました。
ComfyUIとは何か
ComfyUIは、comfyanonymous氏(現在はComfy-Org)が開発・公開しているオープンソースのAI生成GUIフレームワークです。画像生成だけでなく、動画生成・3D生成・音声処理・テキスト生成まで対応するマルチモーダルなプラットフォームへと進化しています。
主な特徴
- ノードベースのビジュアルエディタにより、複雑なAI生成パイプラインを視覚的に構築・共有できる
- SDXL・SD3.5・FLUX・LTX-Video・Wan2.7・HunyuanVideoなど最新モデルに完全対応
- VRAM 4GBのGPUでも動作するメモリ効率の高い設計(低VRAM・CPU専用モード搭載)
- ワークフローはJSONファイルとして保存・読み込み・共有可能
- REST APIとして他のアプリから呼び出せるバックエンド機能を標準搭載
- ComfyUI Managerによるカスタムノードの一元管理
- NVIDIA・AMD・Apple Silicon・Intel Arc・CPUの幅広いハードウェアに対応
基本情報
| 項目 | 内容 |
|---|---|
| 開発元 | comfyanonymous氏(個人→Comfy-Org) |
| ライセンス | GNU General Public License v3.0 |
| 初回リリース | 2023年1月 |
| 最新バージョン | v0.19.0(2026年4月13日) |
| 公式リポジトリ | github.com/comfyanonymous/ComfyUI |
| 公式サイト | comfy.org |
| 公式ドキュメント | docs.comfy.org |
最新リリース情報(2026年)
ComfyUIは2026年に入ってから急速なペースでアップデートが続いています。公式Changelogから直近6ヶ月の主要変更点を整理します。
v0.19.0(2026年4月13日)— 最新版
- LTX2 reference audio対応:音声を参照としたビデオ生成ワークフローが可能に
- Qwen3.5テキスト生成・Ace Step 1.5 XLモデルのサポートを追加
- RT-DETRv4オブジェクト検出ノードを統合
- CURVEノードの追加:トーンカーブ操作・制御信号の精密な調整が可能
- GLSLシェーダー機能の強化
- RAMキャッシュとモデルRAM管理の統合によりロード時間を短縮
- Seedance 2.0の対応(2026年4月13日同時リリース)
v0.18.2(2026年3月25日)
- Grok Reference to VideoおよびGrok Video Extend パートナーノードを追加
- バグ修正・安定性向上
v0.18.1(2026年3月23日)
- CannyノードのFP16互換性の修正
- FP16中間値を使用したサンプリング問題を解消
- WAN VAE処理における光量・色調の問題を修正
v0.18.0(2026年3月21日)
- –fp16-intermediatesフラグの導入:中間テンソルをFP16で保持することでVRAMを大幅に削減
- LTXおよびWAN VAEモデルのメモリ最適化を大幅強化
- mxfp8精度サポートを追加
- AMD gfx1150 GPU向けにPyTorch Attentionを有効化
v0.17.0(2026年3月13日)
- モジュラーアセットアーキテクチャを実装(バックグラウンドシーディングを含む)
- Flux 2 Klein KV Cacheサポート:FLUX.2 Kleinモデルのパフォーマンス向上
- Painterノードの追加:インペインティング・マスク作成を直感的に操作可能
- モデルパッチシステムのクリーンアップ機能を強化
v0.16.0(2026年3月5日)
- ダイナミックVRAMモードがデフォルトに:使用中のモデルに応じてVRAM割り当てを自動最適化
- アスペクト比プリセット付きResolutionSelectorノードを追加
- ACE-Step 1.5 lycoris互換性を導入
- ネイティブLongCat-Image実装
v0.15.0(2026年2月24日)
- BBoxウィジェットでバウンディングボックス選択をUI上で直接操作可能に
- 音声処理向け3バンドイコライザーを追加
- Gemma3/Qwen3を使った基本テキスト生成機能の統合
- GLSLシェーダーノードの導入
- ElevenLabs APIノードを追加
他ツールとの比較
ComfyUIと主要なStable Diffusion系GUIを比較します(各ツールの情報は2026年4月時点)。
| 項目 | ComfyUI v0.19.0 | A1111 v1.10.x | SD WebUI Forge v2.x | Fooocus v2.5.x |
|---|---|---|---|---|
| UIスタイル | ノードベース | フォームベース | フォームベース | シンプルフォーム |
| 対象ユーザー | 中〜上級者 | 初〜中級者 | 初〜中級者 | 初心者 |
| VRAM最小 | 4GB(低VRAMモード時) | 4GB | 4GB | 4GB |
| 生成速度 | 最速(バッチで2倍以上) | 標準 | A1111より30〜75%高速 | 中程度 |
| FLUX対応 | 完全対応(ネイティブ) | 拡張機能要 | 拡張機能要 | 限定対応 |
| 動画生成 | ネイティブ対応 | 拡張機能要 | 拡張機能要 | 非対応 |
| ワークフロー共有 | JSON形式で完全共有 | プリセット共有 | プリセット共有 | 限定的 |
| カスタムノード | 豊富(数百種類) | 拡張機能が豊富 | A1111拡張互換 | 限定的 |
| REST API | 標準搭載 | APIあり | APIあり | 限定的 |
| 学習コスト | 高い | 低い | 低〜中 | 非常に低い |
| ライセンス | GPL-3.0 | AGPL-3.0 | AGPL-3.0 | GPL-3.0 |
どのツールを選ぶべきか
- ComfyUI:ワークフローの完全制御が必要、動画生成・複数モデルの組み合わせ・API連携を行いたいパワーユーザーに最適
- A1111:初心者で拡張機能のエコシステムを活かしたい場合に最適
- Forge:A1111の操作感を維持しつつ速度・VRAM効率を改善したい場合に最適
- Fooocus:とにかく簡単に始めたい初心者に最適
メリット・デメリット
メリット
- ワークフローを完全に視覚化・カスタマイズできるため、複雑なパイプラインも直感的に構築できる
- 生成速度がA1111比で最大2倍以上高速(ダイナミックVRAM最適化の効果)
- SDXL・SD3.5・FLUX・LTX-Video・Wan・HunyuanVideoなど最新モデルへの対応が最も早い
- JSONファイルでワークフローを完全に共有できるため、他者のノウハウをそのまま再現できる
- REST APIが標準搭載されており、Pythonスクリプトや外部アプリとの連携が容易
- ComfyUI Managerにより数百種類のカスタムノードをGUIで管理できる
- Desktop版(Windows・macOS)が提供されており、インストールが簡単になった
- VRAM 4GB以下の環境でも–lowvramオプションや–fp16-intermediatesで動作させられる
- NVIDIA RTX 50シリーズ使用時はNVFP4形式でFP16比2.5倍高速化・VRAM60%削減が可能
デメリット
- ノードベースの操作に慣れるまでの学習コストが高く、初心者には敷居が高い
- A1111向けに作られた拡張機能はそのまま動作しない(ComfyUI用カスタムノードが別途必要)
- 日本語インターフェースが公式には存在しない(一部カスタムノードで対応可能)
- カスタムノードの組み合わせによっては依存関係の競合が発生することがある
- ワークフローが複雑になるほど画面が見づらくなる傾向がある
動作要件
OS別サポート状況
| OS | サポート状況 | 推奨バージョン |
|---|---|---|
| Windows | 完全サポート(Desktop版・Portable版あり) | Windows 10 / 11(64bit) |
| macOS | 完全サポート(Desktop版あり) | macOS 13 Ventura以降(Apple Silicon推奨) |
| Linux | 完全サポート(手動インストール) | Ubuntu 22.04 LTS以降 |
ハードウェア要件
| 項目 | 最小構成 | 推奨構成 |
|---|---|---|
| GPU(NVIDIA) | GTX 1060 6GB(CUDA 11対応以降) | RTX 3080 10GB以上 |
| GPU(AMD) | RX 6700(Linux:ROCm 7.2対応) | RX 7900 XTX(Linux推奨) |
| GPU(Apple) | M1(8GB統合メモリ) | M2 Pro / M3 Max以上 |
| GPU(Intel) | Arc A770 16GB | Arc A770 16GB |
| VRAM | 4GB(–lowvramモード使用時) | 8GB以上(SD1.5/SDXL)、16GB以上(FLUX) |
| RAM | 8GB | 16GB以上 |
| ストレージ | 20GB(本体のみ) | 100GB以上(モデル含む) |
| Python | 3.12 | 3.13(カスタムノード互換性重視の場合は3.12) |
| PyTorch | 2.4.0 | 最新安定版 |
GPUドライバーの要件
- NVIDIA:CUDA 13.0対応のStudioドライバーを推奨。古いカード(GTX 10シリーズ等)はCUDA 12.6のPyTorchを使用
- AMD Linux:ROCm 7.2対応ドライバーが必要(RDNA 3以降を推奨)
- AMD Windows:RDNA 3・3.5・4アーキテクチャのみ実験的サポート
- Apple Silicon:macOS 13以降でMPS(Metal Performance Shaders)が自動的に使用される
インストール手順
ComfyUIのインストール方法は主に4種類あります。初心者にはDesktop版またはWindows Portable版を推奨します。
方法1:Desktop版(最も簡単・推奨)
ComfyUIのDesktop版は公式サイト(comfy.org/download)からダウンロードできます。Windows・macOSに対応しており、PythonやGitのインストールは不要です。ComfyUI Managerも最初からプリインストールされています。
- 公式サイトにアクセスし、OSに対応したインストーラーをダウンロード
- インストーラーを実行し、画面の指示に従ってインストール
- 初回起動時にGPUを自動検出し、最適な設定で起動
- ブラウザが自動で開き、
http://127.0.0.1:8188にアクセスされる
方法2:Windows Portable版(Python不要・軽量)
Windows Portable版は、専用のPython環境を同梱した自己完結型パッケージです。PCへのPythonインストールは不要で、7z形式のアーカイブを展開するだけで使用できます。
ダウンロードと展開
- GitHub Releasesページにアクセス
- 最新のリリース(v0.19.0)から以下のいずれかをダウンロード:
ComfyUI_windows_portable_nvidia.7z:NVIDIA GPU(CUDA 13.0対応)ComfyUI_windows_portable_nvidia_cu126.7z:古いNVIDIA GPU(GTX 10シリーズ等)
- 7-Zip(無料)でアーカイブを展開。展開先は
C:\ComfyUI等、パスにスペースや日本語を含まない場所を推奨
起動
# NVIDIAのGPUを使う場合(ダブルクリックでも可)
run_nvidia_gpu.bat
# CPUのみで動作させる場合
run_cpu.bat起動後、コマンドウィンドウにTo see the GUI go to: http://127.0.0.1:8188と表示されたら、ブラウザでそのURLを開きます。コマンドウィンドウは閉じないでください。
アップデート方法
# Portable版のアップデート
update\update_comfyui.bat
# Python依存パッケージも含めてアップデートする場合
update\update_comfyui_and_python_dependencies.bat方法3:comfy-CLI(中級者向け・クロスプラットフォーム)
comfy-CLIはコマンドラインからComfyUIをインストール・管理できるツールです。Windows・Mac・Linuxで動作します。
# comfy-CLIのインストール
pip install comfy-cli
# ComfyUIのインストール(対話形式でGPUを選択)
comfy install
# 起動
comfy launch方法4:手動インストール(Linux・上級者向け)
すべてのOSで動作する最も柔軟なインストール方法です。GitとPython 3.12/3.13が事前に必要です。
Windows(手動)
# Git for WindowsとPython 3.12以上が必要
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 仮想環境の作成(推奨)
python -m venv venv
venv\Scripts\activate
# NVIDIA GPU用PyTorchのインストール(CUDA 13.0対応)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
# 依存パッケージのインストール
pip install -r requirements.txt
# 起動
python main.pymacOS(Apple Silicon)
# Homebrewが必要(未インストールの場合)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# pyenvで正しいPythonバージョンを管理
brew install pyenv
pyenv install 3.13.2
pyenv global 3.13.2
# ComfyUIのクローン
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 仮想環境の作成
python3 -m venv venv
source venv/bin/activate
# Apple Silicon(MPS)用PyTorchのインストール
pip install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
# 依存パッケージのインストール
pip install -r requirements.txt
# 起動(MPSが自動的に使用される)
python main.pyLinux(NVIDIA GPU)
# 必要なパッケージのインストール(Ubuntu/Debian)
sudo apt update
sudo apt install -y python3.13 python3.13-venv git
# ComfyUIのクローン
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 仮想環境の作成
python3.13 -m venv venv
source venv/bin/activate
# NVIDIA GPU用PyTorchのインストール(CUDA 13.0対応)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
# 依存パッケージのインストール
pip install -r requirements.txt
# 起動
python main.pyLinux(AMD GPU・ROCm)
# ROCm 7.2のインストール(Ubuntu 22.04の場合)
# AMDの公式手順に従いROCm 7.2をインストール
# https://rocm.docs.amd.com/
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
python3 -m venv venv
source venv/bin/activate
# AMD GPU用PyTorchのインストール(ROCm 7.2)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm7.2
pip install -r requirements.txt
python main.py初期設定
モデルのダウンロードと配置
ComfyUI本体にはモデルファイルが含まれていません。別途ダウンロードしてComfyUIのモデルフォルダに配置する必要があります。
モデルの配置場所
| モデルの種類 | 配置フォルダ | 拡張子 |
|---|---|---|
| チェックポイント(SD1.5/SDXL等) | ComfyUI/models/checkpoints/ | .safetensors / .ckpt |
| FLUX拡散モデル | ComfyUI/models/diffusion_models/ | .safetensors |
| VAE | ComfyUI/models/vae/ | .safetensors / .pt |
| LoRA | ComfyUI/models/loras/ | .safetensors |
| ControlNet | ComfyUI/models/controlnet/ | .safetensors / .pth |
| CLIPテキストエンコーダー | ComfyUI/models/clip/ | .safetensors |
| アップスケーラー | ComfyUI/models/upscale_models/ | .pth / .safetensors |
入門用モデルの入手先
- Civitai:SD1.5・SDXL・FLUX対応のチェックポイント・LoRAが多数公開
- Hugging Face:公式モデル・テキストエンコーダー・VAE等の入手に利用
# コマンドラインでダウンロードする場合の例(wget使用)
cd ComfyUI/models/checkpoints/
wget "https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0.safetensors"起動オプション一覧
ComfyUIはコマンドラインオプションで動作をカスタマイズできます。主要なオプションを以下に示します。
# VRAMが4〜6GBの場合(低VRAM最適化)
python main.py --lowvram
# VRAM 4GB未満・非常に少ないVRAMの場合
python main.py --novram
# FP16中間値でVRAMをさらに削減(v0.18.0以降)
python main.py --fp16-intermediates
# CPUのみで生成(非常に低速)
python main.py --cpu
# 別のIPアドレス・ポートで起動(ネットワーク越しにアクセスしたい場合)
python main.py --listen 0.0.0.0 --port 8188
# 複数GPU環境でGPUを指定
python main.py --cuda-device 1
# PyTorch Compileで高速化(初回起動時にコンパイルが走る)
python main.py --torch-compileComfyUI Managerのインストール(Portable版の場合)
Desktop版にはComfyUI Managerがプリインストールされていますが、Portable版は手動インストールが必要です。
# Windows Portable版の場合:custom_nodesフォルダにクローン
cd ComfyUI\custom_nodes
git clone https://github.com/Comfy-Org/ComfyUI-Manager.git
# ComfyUIを再起動すると自動的に有効になるまたは、ComfyUI-ManagerのGitHubページからscripts/install-manager-for-portable-version.batをダウンロードしてPortableフォルダ内で実行する方法もあります。
基本的な使い方
ノードエディタの基本操作
ComfyUIのメイン画面はノードエディタです。ノードとは処理の単位であり、それぞれ入力ポート(左側)と出力ポート(右側)を持ちます。ノード間をワイヤー(線)で接続することで処理フローを定義します。
| 操作 | 方法 |
|---|---|
| 画面移動 | 右ドラッグ(またはスペース+ドラッグ) |
| ズーム | マウスホイール |
| ノードの追加 | 右クリック→「Add Node」または検索ボックスでノード名を入力 |
| ノードの移動 | 左ドラッグ |
| ノードの削除 | 選択してDelete / Backspace |
| ノードの複製 | Ctrl+C / Ctrl+V |
| ワイヤーの接続 | 出力ポートから入力ポートへドラッグ |
| ワイヤーの切断 | Ctrl+ドラッグで切断、またはワイヤーを右クリック |
| ノードの全選択 | Ctrl+A |
| 元に戻す | Ctrl+Z |
| ワークフロー保存 | Ctrl+S |
| ワークフロー読み込み | Ctrl+O |
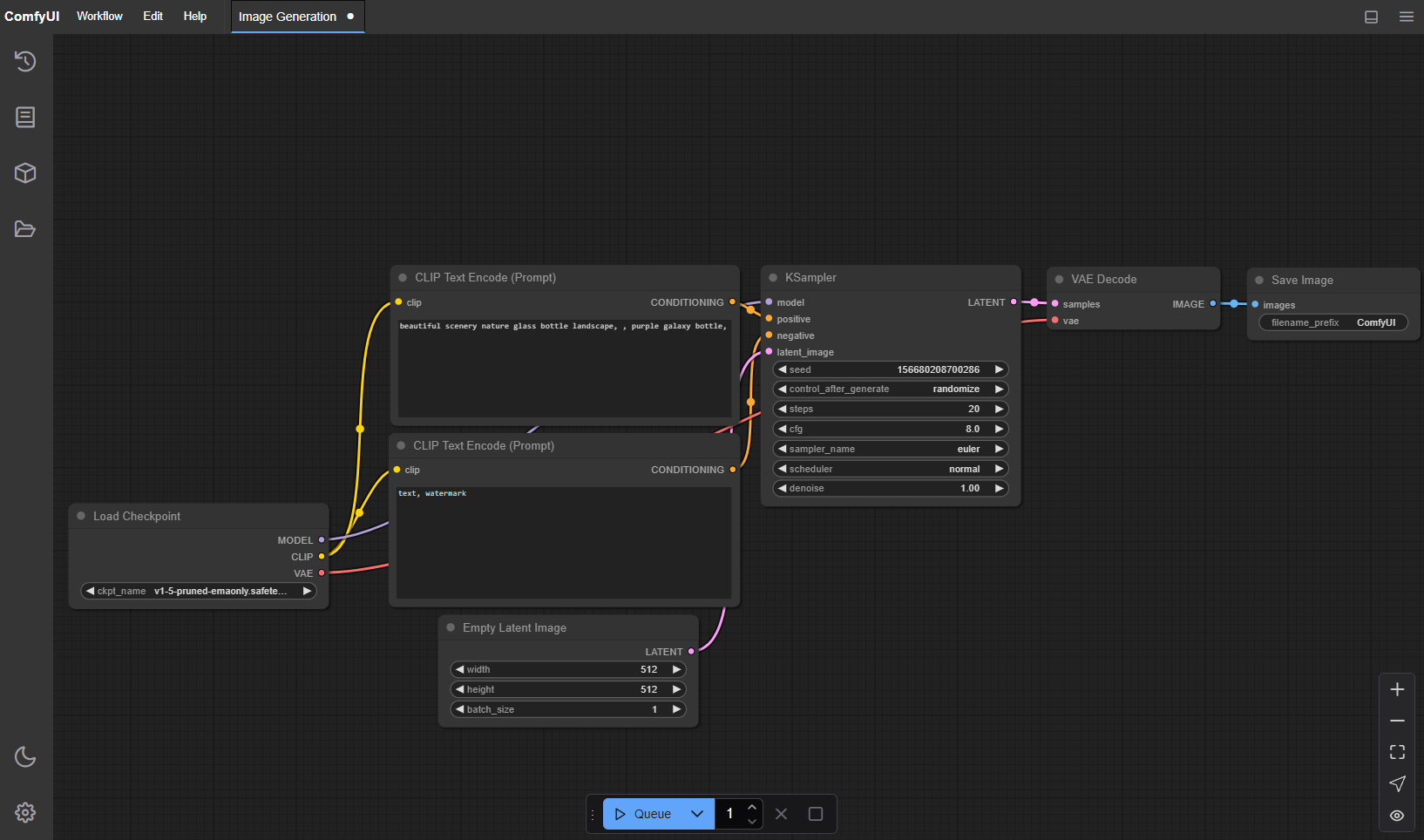
デフォルトワークフロー(txt2img)の理解
ComfyUIを起動すると、標準的なtxt2imgワークフローがロードされています。このワークフローは以下の6種類のノードで構成されています。
- Load Checkpoint:モデルファイル(.safetensors)をロードし、MODEL・CLIP・VAEを出力する
- CLIP Text Encode(Positive):プロンプトを処理し、CONDITIONINGを生成する
- CLIP Text Encode(Negative):ネガティブプロンプトを処理する
- KSampler:ノイズから画像を生成するサンプリング処理の中心ノード。ステップ数・CFGスケール・サンプラー・スケジューラを設定する
- VAE Decode:潜在空間の表現をピクセル画像に変換する
- Save Image:生成された画像を保存する
基本的なtxt2img生成の手順
- 「Load Checkpoint」でモデルを選択(
models/checkpoints/内のファイルが表示される) - 「CLIP Text Encode(Positive)」のテキスト欄にプロンプトを入力(例:
a beautiful landscape, masterpiece, high quality) - 「CLIP Text Encode(Negative)」にネガティブプロンプトを入力(例:
blurry, low quality, deformed) - 「Empty Latent Image」ノードで解像度を設定(SDXLは1024×1024推奨、SD1.5は512×512)
- 「KSampler」でサンプリング設定を調整:
- steps:20〜30(品質と速度のバランス)
- cfg:7.0(プロンプトの忠実度。高いほど忠実だが硬くなる傾向がある)
- sampler_name:
eulerまたはdpmpp_2mが汎用的で推奨 - scheduler:
normalまたはkarras
- 右パネルの「Queue Prompt」ボタンをクリックして生成を開始
img2imgの基本
既存の画像を参考にして新しい画像を生成するimg2imgは、「Load Image」ノードと「VAE Encode」ノードを使います。
- 「Load Image」ノードで参照画像を読み込む
- 「VAE Encode」ノードで画像を潜在空間に変換する
- KSamplerの
denoiseパラメータを0.4〜0.8に設定(低いほど元画像に近い) - 「Empty Latent Image」の代わりに「VAE Encode」の出力をKSamplerのLATENT入力に接続する
ワークフローの保存と読み込み
ComfyUIで生成した画像には、ワークフローのJSON情報が自動的に埋め込まれます。その画像をComfyUIのブラウザ画面にドラッグ&ドロップするだけで、そのときのワークフローを完全に復元できます。これはComfyUIの非常に便利な機能の一つです。
# ワークフローをJSONとして手動保存するショートカット
# Ctrl+S → workflow.json として保存
# 保存済みJSONの読み込み
# Ctrl+O → ファイルを選択実践的な使い方
ケース1:FLUX.1 Devを使ったテキスト→画像生成
FLUX.1は2024年にBlack Forest Labsが公開した高品質テキスト→画像生成モデルで、現在最も人気の高いモデルの一つです。ComfyUIはFLUXに完全対応しており、公式もComfyUIをFLUXの標準インターフェースとして採用しています。
必要なファイルのダウンロード
- FLUXモデル:
flux1-dev.safetensors→ComfyUI/models/diffusion_models/に配置 - テキストエンコーダー(T5):
t5xxl_fp16.safetensors→ComfyUI/models/clip/に配置 - テキストエンコーダー(CLIP):
clip_l.safetensors→ComfyUI/models/clip/に配置 - VAE:
ae.safetensors→ComfyUI/models/vae/に配置
これらのファイルはHugging Face(FLUX.1-dev)から入手できます(アカウント登録・利用規約への同意が必要)。
FLUXワークフローの主要ノード
FLUXは従来のSDモデルとは異なるワークフロー構成が必要です。
- Load Diffusion Model:
flux1-dev.safetensorsを読み込む(「Load Checkpoint」ではない点に注意) - DualCLIPLoader:
t5xxl_fp16.safetensorsとclip_l.safetensorsの2つのテキストエンコーダーを同時にロード - VAE Loader:
ae.safetensorsをロード - CLIP Text Encode (Flux):プロンプト入力(FLUXはネガティブプロンプトを使用しない)
- FluxGuidance:guidanceパラメータを設定(推奨値:3.5)
- KSampler:steps=20、sampler=euler、scheduler=simple
- VAE Decode → Save Image
VRAM節約のヒント:FLUX.1 DevはFP16で約12GBのVRAMが必要です。VRAMが8GB以下の場合はflux1-dev-Q4_K_M.gguf等のGGUF量子化バージョンをHugging Face(city96/FLUX.1-dev-gguf)からダウンロードし、models/diffusion_models/に配置してください。GGUF版は「Load Diffusion Model」ノードではなく「UnetLoaderGGUF」カスタムノードが必要です(ComfyUI Managerから「ComfyUI-GGUF」をインストール)。
ケース2:ControlNetを使った構図制御
ControlNetは入力画像(エッジ・深度・ポーズ等)を参考に、構図を制御しながら画像を生成できる機能です。特定のポーズや構図を再現したい場合に非常に有効です。
必要なファイル
- ControlNetモデル(例:
control_v11p_sd15_canny.pth)→models/controlnet/に配置 - ベースモデル(SD1.5またはSDXL対応のものを使用。ControlNetとベースモデルのアーキテクチャを合わせる)
ワークフロー構成
- Load Image:制御に使う参照画像を読み込む
- Canny Edge Detection(またはDepth/OpenPoseなど):前処理ノードでControlNet入力画像を生成
- Load ControlNet Model:対応するControlNetモデルをロード
- Apply ControlNet:ControlNetモデル・条件付け・制御画像を接続し、強度(strength)を設定(0.7〜1.0推奨)
- 以降のサンプリング・デコードは通常のtxt2imgと同様
ケース3:LoRAによるスタイル適用
LoRA(Low-Rank Adaptation)は特定のスタイルやキャラクターを学習した小型モデルです。ベースモデルと組み合わせることで、特定の画風やキャラクターを安定的に生成できます。
LoRAノードの追加手順
- 「Load Checkpoint」と「KSampler」の間にLoad LoRAノードを挿入
- Load LoRAノードでLoRAファイルを選択(
models/loras/に配置済みのファイルから選択) strength_model:モデルへの影響強度(0.5〜1.0が目安。1.0が最大効果)strength_clip:CLIPエンコーダーへの影響強度(通常はモデルと同じ値で問題なし)- 複数のLoRAを積み重ねる場合は、Load LoRAノードをチェーン状に接続する(LoRAの出力を次のLoRAの入力へ)
# LoRAファイルの配置場所
ComfyUI/
models/
loras/
style_anime.safetensors
character_realistic.safetensors
detail_enhancer.safetensors応用・カスタマイズ
ComfyUI Managerでカスタムノードを管理する
ComfyUI Managerは数百種類のカスタムノードをGUIから管理できるツールです。インストール・アップデート・削除・競合検出が可能です。
カスタムノードのインストール手順
- ComfyUI右パネルの「Manager」ボタンをクリック
- 「Install Custom Nodes」を選択
- 検索ボックスにノード名を入力(例:
ComfyUI-GGUF、ComfyUI-Impact-Pack等) - 「Install」ボタンをクリック
- インストール完了後、ComfyUIを再起動して「Refresh」
おすすめカスタムノード一覧(2026年4月時点)
| ノード名 | 用途 |
|---|---|
| ComfyUI-GGUF | GGUF量子化モデルの読み込み(低VRAM環境に必須) |
| ComfyUI-Impact-Pack | 顔検出・顔修正(ADetailer相当)・セグメンテーション |
| ComfyUI-Advanced-ControlNet | 高度なControlNet操作(アニメーション・バッチ対応) |
| ComfyUI_IPAdapter_plus | 参照画像からスタイル・構図を転写するIPAdapter |
| efficiency-nodes-comfyui | ワークフローを簡潔に書けるユーティリティノード |
| ComfyUI-Frame-Interpolation | 動画のフレーム補間(RIFE等) |
| ComfyUI-VideoHelperSuite | 動画の読み込み・書き出し・フレーム処理 |
| was-node-suite-comfyui | 500以上の多機能ユーティリティノード群 |
App View(簡易インターフェース)の活用
v0.16.0以降で導入されたApp Viewは、ノードエディタを非表示にしてシンプルなUIでワークフローを実行できるモードです。プロンプト入力と基本パラメータ調整だけを表示し、ノードグラフの知識がなくてもComfyUIを利用できます。右上の「App View / Node View」スイッチで切り替えられます。ノウハウをApp View対応ワークフローとして配布することで、非技術者にも使ってもらいやすくなります。
ワークフローのAPI化
ComfyUIはREST APIとして外部から呼び出せます。PythonスクリプトやWebアプリからComfyUIを制御する場合に使用します。
import json
import urllib.request
# ワークフローJSONを読み込む
with open("workflow.json", "r") as f:
workflow = json.load(f)
# プロンプトを動的に変更する例
workflow["6"]["inputs"]["text"] = "a cat sitting on a mountain"
# APIエンドポイントに送信
data = json.dumps({"prompt": workflow}).encode("utf-8")
req = urllib.request.Request("http://127.0.0.1:8188/prompt", data=data)
with urllib.request.urlopen(req) as response:
result = json.loads(response.read())
print(f"Prompt ID: {result['prompt_id']}")extra_model_paths.yamlによる外部モデルフォルダの参照
A1111やForgeで管理しているモデルフォルダをComfyUIから参照させることができます。モデルの重複ダウンロードを防ぎ、ストレージを節約できます。
# ComfyUI/extra_model_paths.yaml
a1111:
base_path: C:/stable-diffusion-webui/
checkpoints: models/Stable-diffusion
loras: models/Lora
vae: models/VAE
controlnet: models/ControlNet
upscale_models: models/ESRGANパフォーマンス最適化
VRAM使用量の削減
ComfyUIはVRAM最適化機能が充実しています。GPUのVRAMに応じて以下の設定を組み合わせます。
| VRAM | 推奨設定 | 効果 |
|---|---|---|
| 16GB以上 | デフォルト(Dynamic VRAM) | 最高速度 |
| 8〜16GB | --fp16-intermediates | 約20〜30%のVRAM削減 |
| 6〜8GB | --lowvram + --fp16-intermediates | 大幅なVRAM削減、速度低下あり |
| 4〜6GB | --novram | システムRAMを使用、低速 |
| 4GB未満 | --cpuまたはGGUFモデル使用 | 非常に低速 |
生成速度の最適化
- ダイナミックVRAMモード(v0.16.0以降デフォルト):モデルをVRAMに可能な限り保持し、スワップを最小化する
- NVIDIA RTX 50シリーズ使用時:NVFP4形式でFP16比2.5倍高速化、VRAM60%削減が可能。RTX 40/30シリーズはFP8で約1.5倍高速化
- サンプラーの選択:
dpmpp_2m+karrasスケジューラはステップ数20で高品質・高速のバランスが良い - ステップ数の調整:FLUXは20ステップで十分な品質。SD1.5は15〜20ステップで良好な結果が得られる
- Tiled VAE:高解像度画像(2048×2048以上)のVAEデコード時にOOMを防止するカスタムノード。「Tiled KSampler」も組み合わせることで大型解像度に対応
- PyTorch Compileの活用:起動オプションに
--torch-compileを追加すると、初回コンパイル後の生成が約20〜40%高速化
# 低VRAM + 速度重視の最適起動コマンド例(8GB VRAM)
python main.py --fp16-intermediates
# VRAM 6GB環境での起動例
python main.py --lowvram --fp16-intermediates
# Torch Compileを有効化(初回起動に時間がかかるが以降は高速)
python main.py --torch-compileよくあるエラーとトラブルシューティング
エラー1:CUDA out of memory(CUDAメモリ不足)
症状:生成中にブラウザが「Reconnecting…」ループに入る。またはコンソールにtorch.cuda.OutOfMemoryError: CUDA out of memoryが表示される。
原因:設定した解像度・バッチサイズ・モデルサイズに対してGPUのVRAMが不足している。
対処法:
- 起動オプションに
--lowvramまたは--novramを追加 - 起動オプションに
--fp16-intermediatesを追加(v0.18.0以降) - 解像度を下げる(例:1024×1024 → 768×768)
- FLUXモデルの場合はGGUF量子化版(Q4_K_M等)を使用
- ComfyUIを再起動してVRAMをクリア
エラー2:モデルが見つからない(Missing nodes / Model not found)
症状:ワークフロー読み込み時に「Missing nodes」または「Model not found」とオレンジ色の警告が表示される。ノードが赤くハイライトされる。
原因:(1) 必要なモデルファイルが正しいフォルダに配置されていない。(2) 必要なカスタムノードがインストールされていない。
対処法:
- 「Missing nodes」の場合:ComfyUI Managerを開き「Install Missing Custom Nodes」を実行
- 「Model not found」の場合:モデルファイルが正しいフォルダにあるか確認(
models/checkpoints/など) - ComfyUIの「Refresh」ボタン(右パネル)でモデルリストを更新
- ファイル名にスペースや日本語が含まれる場合は半角英数字にリネームして再試行
エラー3:カスタムノードの依存関係競合
症状:ComfyUI起動時にコンソールにImportErrorやModuleNotFoundErrorが表示され、特定のカスタムノードが読み込まれない。
原因:複数のカスタムノードが異なるバージョンの同じライブラリに依存している。
対処法:
- ComfyUI ManagerのConflict Detectionを使用して競合を特定
- 問題のあるカスタムノードを一時的に無効化してComfyUIを再起動し、原因を切り分ける
- ComfyUI Managerの「Fix」機能で依存関係を自動修復
- 手動修復の場合はカスタムノードのフォルダ内で依存パッケージを再インストール
# 特定カスタムノードの依存パッケージを再インストール(Portable版の場合)
cd ComfyUI\custom_nodes\[ノード名]
..\..\python_embeds\python.exe -m pip install -r requirements.txtエラー4:Windowsでrun_nvidia_gpu.batを実行してもすぐ閉じる
症状:batファイルをダブルクリックするとコマンドウィンドウが一瞬表示されてすぐに閉じる。
原因:(1) NVIDIAドライバーが古い。(2) Pythonの依存パッケージが壊れている。(3) インストールパスに問題がある(日本語・スペースが含まれる等)。
対処法:
- batファイルをコマンドプロンプトから直接実行してエラーメッセージを確認
- NVIDIAドライバーを最新版に更新
- Portable版の場合は
update\update_comfyui.batとupdate\update_comfyui_and_python_dependencies.batを順に実行
# コマンドプロンプトから直接起動(エラーメッセージを確認するため)
cd C:\ComfyUI_windows_portable
.\run_nvidia_gpu.bat
# 画面に表示されるエラーメッセージを確認エラー5:生成画像が真っ黒・真っ白になる
症状:画像生成は完了するが、出力が真っ黒または真っ白の画像になる。
原因:主にVAEの問題。SD1.5系モデルにSDXL用VAEを使っている(またはその逆)。あるいはVAEがFP16で精度問題を起こしている。CFGスケールが異常に高い(20以上)場合も真っ白になる。
対処法:
- 使用しているベースモデルに対応したVAEに切り替える
- 「VAE Loader」ノードで
vae-ft-mse-840000-ema-pruned.safetensors(SD1.5用の安定VAE)を試す - FLUXの場合は専用VAE(
ae.safetensors)が必須であることを確認 - KSamplerの
cfg値が高すぎる(15以上)場合は7〜8程度に下げる
エラー6:AMD GPUが認識されない(Windows)
症状:AMD GPUを使用しているのにCPUモードで動作する、またはGPUが検出されない。
原因:WindowsのAMD GPUサポートはRDNA 3・3.5・4アーキテクチャのみの実験的サポートです。RX 6000シリーズ以前は対象外です。
対処法:
- GPUがRDNA 3以降(RX 7000シリーズ)であることを確認
- AMD ROCm対応のPyTorchを手動インストール
- 安定して使いたい場合はLinux環境への移行を検討(AMDはLinux+ROCm 7.2の方が安定している)
エラー7:ワークフローが途中で止まる・プログレスバーが動かない
症状:生成キューに入っているが、プログレスバーが動かなくなる。ブラウザは接続されているが生成が進まない。
対処法:
- ブラウザで
http://127.0.0.1:8188/queueにアクセスしてキューの状態を確認 - 右パネルの「Clear Queue」でキューをクリアし再試行
- ComfyUIを再起動してVRAMをクリア
- 使用しているカスタムノードを最新版にアップデート(ComfyUI Managerの「Update All」機能を使用)
- 問題のあるカスタムノードを無効化して動作確認(ComfyUI Manager → 「Disable」)
おすすめの組み合わせ・連携
ComfyUI + Civitai(モデル管理)
CivitaiはSD・FLUX・LoRA・ControlNetなどのモデルを共有するコミュニティプラットフォームです。ComfyUI Managerの「Civitai Browser」機能から直接ブラウジング・ダウンロードが可能です。モデルのレビューや作例も豊富に掲載されているため、試したいモデルを探す際の第一候補です。
ComfyUI + Ollama(テキスト生成連携)
ComfyUIのプロンプト生成部分にOllamaのローカルLLMを連携させることで、自動的にプロンプトを生成・拡張できます。ComfyUI-Ollamaカスタムノードを使用します。
# ComfyUI Managerから「ComfyUI-Ollama」を検索してインストール後、
# OllamaGenerateNodeにモデル名(例:llama3.3:70b)とプロンプトシードを接続するComfyUI + AUTOMATIC1111(モデル共有・共存)
A1111とComfyUIを同じPCで共存させ、extra_model_paths.yamlを使ってモデルフォルダを共有することで、ストレージを節約しながら両方のツールを使い分けられます。詳しくは「応用・カスタマイズ」セクションの設定例を参照してください。
ComfyUI + n8n / Make(自動化パイプライン)
ComfyUIのREST APIを外部ツールから呼び出すことで、画像生成を完全自動化できます。n8nやMake(旧Integromat)などのノーコード自動化ツールとの組み合わせで、プロンプトの自動生成から画像の配信・保存まで一気通貫のパイプラインを構築できます。
推奨PCスペック
ComfyUIの使用目的別に推奨PCスペックを3段階で示します。
| 項目 | 入門(SD1.5/SDXLのみ) | 標準(FLUX対応) | ハイエンド(動画/3D生成含む) |
|---|---|---|---|
| GPU | RTX 3060 12GB / RX 6700 XT 12GB | RTX 4070 12GB / RX 7900 GRE 16GB | RTX 4090 24GB / RTX 5090 32GB |
| VRAM | 8〜12GB | 12〜16GB | 24GB以上 |
| CPU | Core i5 / Ryzen 5(8コア以上) | Core i7 / Ryzen 7(12コア以上) | Core i9 / Ryzen 9(16コア以上) |
| RAM | 16GB | 32GB | 64GB以上 |
| ストレージ | SSD 512GB(OS+本体) | SSD 1TB以上(NVMe推奨) | NVMe SSD 2TB以上 |
| SD1.5 512×512生成速度目安 | 約5〜8秒 | 約2〜3秒 | 約0.5〜1秒 |
| FLUXの実用性 | GGUF量子化必須 | FP8またはFP16で動作可 | FP16フルスペックで動作 |
| 概算費用 | 10〜15万円(GPU単体) | 20〜30万円 | 50万円以上 |
Apple Siliconの目安
| モデル | 統合メモリ | 用途目安 |
|---|---|---|
| M1 / M2 | 8GB | SD1.5のみ。FLUXはGGUF Q3/Q4必須、速度は遅い |
| M1 Pro / M2 Pro | 16〜32GB | SDXLは快適。FLUX FP8で動作可 |
| M2 Max / M3 Max | 32〜64GB | FLUX FP16・動画生成が実用的 |
| M2 Ultra / M3 Ultra | 64〜192GB | 大規模動画生成モデルも快適に動作 |
まとめ
ComfyUIは2026年4月現在、最新版v0.19.0において、画像・動画・音声・テキストを統合したマルチモーダルAI生成プラットフォームへと進化しています。ダイナミックVRAMモードの標準化(v0.16.0)、fp16中間値によるVRAM削減(v0.18.0)、LTX2・Wan2.7・Seedance 2.0等の最新モデルへの対応と、進化のスピードは業界最速クラスです。
学習コストは確かに高いものの、一度習得すれば他のどのツールにも真似できない柔軟性・処理速度・拡張性を手に入れられます。特に以下のような方に強くComfyUIをおすすめします。
- ワークフローを完全にカスタマイズして再現性のある生成を行いたい方
- 最新のFLUX・LTX-Video・Wan等のモデルをいち早く試したい方
- ComfyUIのAPIを使って自動化パイプラインを構築したい開発者
- 低VRAMのGPUでも最大限のパフォーマンスを発揮させたい方
今後の公式ロードマップとして、App View(簡易インターフェース)のさらなる充実、モバイルデバイスへの対応、クラウドとローカルのシームレスな連携が進められています。公式ドキュメント(docs.comfy.org)と公式フォーラム(forum.comfy.org)も積極的に活用しながら、ComfyUIの可能性を最大限に引き出してください。
📦 この記事で紹介した商品
- Stable Diffusion画像生成ガイドブック → Amazonで見る
- NVIDIA GeForce RTX 4070 Ti SUPER → Amazonで見る
- ComfyUI使い方ガイド(1) StableDiffusion WebUIをビジュアルプログラミングのように操作【ワークフロー】【チェックポイント】イン… → Amazonで見る
- CT2K32G56C46S5 [64GB Kit (32GBx2) Crucial DDR5 5600 … → Amazonで見る
- TB NVMe SSD → Amazonで見る
※ 上記リンクはAmazonアソシエイトリンクです。購入いただくと当サイトに紹介料が入ります。

