
Stable Diffusion WebUI(通称AUTOMATIC1111、略してA1111)は、ローカル環境でStable Diffusionによる画像生成を行うためのWebインターフェースとして、2022年の登場以来もっとも広く使われてきた定番ツールです。膨大な日本語チュートリアル、数百種類の拡張機能、CivitAIなどで配布される無数のモデルとの高い互換性が最大の強みです。本記事では、2026年5月時点の最新状況を踏まえ、A1111をゼロからインストールして実用ワークフローを組めるようになるまでを、Windows・Mac・Linuxすべて網羅して徹底解説します。
ただし最初に正直にお伝えします。A1111の本体(mainブランチ)は2024年7月のv1.10.0以降、実質的に開発が停滞しており、最後のタグはv1.10.1(2025年2月付与、コード本体は2024年7月時点で凍結)です。FLUXやStable Diffusion 3.5といった新世代モデル、RTX 50シリーズ(Blackwell)への正式対応は本体には入っていません。本記事はこの現実を隠さず、「2026年のいま、A1111をどう使うべきか、どのフォークに乗り換えるべきか」までを含めた決定版として書いています。
Stable Diffusion WebUI(A1111)とは何か
Stable Diffusion WebUIは、AUTOMATIC1111氏が開発したオープンソースのStable Diffusion用ブラウザGUIです。Python製のGradioフレームワーク上に構築されており、ローカルPCで起動したサーバーにブラウザからアクセスして画像を生成します。クラウドにデータを送らず、生成枚数の制限もなく、商用利用条件はモデルのライセンスにのみ依存します。
初回リリースは2022年8月で、Stable Diffusion v1.4/v1.5の公開と同時期にコミュニティの事実上の標準となりました。「Stable Diffusionを始める=A1111を入れる」という時代が約2年続き、その間に蓄積された日本語の解説記事・YouTube動画・拡張機能の数は他のどのツールも追随できないレベルにあります。これが2026年になってもA1111を学ぶ価値がある最大の理由です。
主な機能
- txt2img(テキストから画像生成)、img2img(画像から画像生成)、インペイント、アウトペイント
- アップスケーラー(R-ESRGAN、ESRGAN、SwinIR、LDSR、ScuNET)と顔補正(GFPGAN、CodeFormer)
- LoRA、LyCORIS、Textual Inversion(埋め込み)、Hypernetworkの読み込み
- ControlNet(拡張機能経由)、Regional Prompter、ADetailer など数百の拡張機能
- X/Y/Z plot によるパラメータ比較、プロンプトのスケジューリング・編集
- チェックポイントのマージ、CLIP interrogator、バッチ処理
- REST API による外部連携(
--apiオプション) - VRAM 4GB から動作可能な省メモリ設計(
--medvram/--lowvram)
ライセンスと開発体制
A1111本体のライセンスはAGPL-3.0です。同梱されるサブモジュールやモデルは別ライセンスのため、商用利用時は使用するチェックポイント(SD1.5、SDXL、各種マージモデル等)のライセンスを必ず個別確認してください。開発はAUTOMATIC1111氏個人を中心としたボランティアベースで、2024年半ば以降はメンテナンスがほぼ止まっています。
最新リリース情報(2026年5月時点)
2026年5月時点で、A1111本体の最新リリースはv1.10.1です。バージョン番号だけ見ると新しそうですが、実態は以下の通りで、ここを誤解すると古い情報を掴むことになります。
- v1.10.0(2024年7月27日リリース)— 最後の機能追加版。Stable Diffusion 3 Medium への対応、新スケジューラー(Align Your Steps、KL Optimal、Beta、Simple、DDIM CFG++ サンプラー)、パフォーマンス改善。
- v1.10.1(タグ付与は2025年2月9日)— 「CPUでのアップスケール修正」のみの極小パッチ。コード本体はv1.10.0からほぼ変わっていません。
- v1.9.4(2024年5月)— setuptools のバージョン固定による起動エラー修正。
masterブランチの最終コミットも2024年7月で止まっており、44件以上のプルリクエストが未マージのまま放置されているとコミュニティの公式Discussion #16670「Future of Automatic1111 for 2025」で議論されています。つまりA1111本体は、FLUX(2024年8月公開)やSD3.5(2024年10月公開)、RTX 50シリーズ(2025年初頭発売、Blackwell世代)への正式対応が一切入っていません。
この状況を受けて、コミュニティの主力は以下のフォークへ移行しました。本記事の比較表・推奨構成はこの現実を反映しています。
- Stable Diffusion WebUI Forge(lllyasviel氏)— A1111互換でVRAM効率と速度を大幅改善。FLUX対応。ただし本家Forgeも実験的方向に進み、2025年6月以降コミットが停滞気味。
- reForge(Panchovix氏)— Forge派生。Python 3.12対応、SageAttention/FlashAttention対応、CFG++サンプラー追加。最終更新2026年4月。
- Forge Classic(Haoming02氏)— 旧Forgeバックエンドを最適化し継続メンテ。2026年5月時点でも活発に更新中。
- SD.Next(vladmandic氏)— A1111から派生した別系統のWebUI。FLUX/SD3.5/新GPUに継続対応し、2026年5月時点でローリングリリースで活発。
他ツールとの比較
2026年5月時点の各ツールの最新版を公式リポジトリで個別確認したうえで比較します。バージョン欄の日付は確認時点の最新リリースまたは最終コミットです。
| 項目 | A1111(本体) | Forge / reForge | ComfyUI | SD.Next |
|---|---|---|---|---|
| 2026年5月時点の版 | v1.10.1(2024年7月凍結) | ローリング(reForge最終 2026年4月) | v0.21.1(2026年5月) | ローリング(2026年5月) |
| 開発状況 | 実質停止 | 本家停滞/フォークは活発 | 非常に活発 | 活発 |
| UI形式 | フォームベース | フォームベース(A1111互換) | ノードベース | フォームベース |
| 学習コスト | 低い | 低い(A1111経験者は即移行可) | 高い | 中 |
| VRAM最小 | 4GB | 4GB(最適化で更に低減) | 4GB | 4GB |
| FLUX対応 | 非対応(本体) | 対応 | 対応 | 対応 |
| SD3.5対応 | 非対応(本体) | 限定的〜対応 | 対応 | 対応 |
| RTX 50系対応 | 要手動対応 | フォークで対応 | 対応 | 対応 |
| 拡張機能の数 | 最多 | 多い(A1111拡張ほぼ流用可) | 多い(カスタムノード) | 中 |
| 日本語情報量 | 圧倒的に多い | 多い | 増加中 | 少なめ |
参考までに、軽量お手軽路線の Fooocus は最新版 v2.5.5(2024年8月)で更新が止まっており、ノードベースで多機能な InvokeAI は安定版 v6.12.0(2026年3月)/v6.13.0 RC3(2026年5月)と活発に開発が続いています。「いまから始めるなら何が活発か」を知っておくことが重要です。
メリット・デメリット
メリット
- 日本語の解説記事・動画・トラブル事例が他ツールより圧倒的に多く、詰まっても検索で解決しやすい
- 拡張機能エコシステムが最大規模。ControlNet、ADetailer、Regional Prompter、Dynamic Prompts などが揃う
- UIがシンプルでパラメータが一画面に並ぶため、初学者がStable Diffusionの仕組みを学ぶのに最適
- SD1.5・SDXLという「枯れた」モデルとの互換性が非常に高く、CivitAIのモデルがほぼそのまま動く
- VRAM 4GBの古いGPUでも起動できる省メモリオプションが充実
デメリット
- 本体の開発が事実上停止。FLUX・SD3.5など2024年8月以降の新モデルは本体非対応
- RTX 50シリーズ(Blackwell)では同梱のPyTorch/CUDAが古く、手動対応が必要
- 新しいPythonでは動かず、Python 3.10.6前提という制約が年々重くなっている
- 速度・VRAM効率はForge系に劣る(同じGPUでForgeの方が高速・省メモリ)
- 未マージのバグ修正PRが多数放置されており、既知の不具合が直らない
動作要件
A1111はNVIDIA GPUを強く推奨します。AMD(ROCm/DirectML)、Intel Arc、Apple Siliconでも動きますが、情報量と安定性はNVIDIAが圧倒的です。
| 項目 | 最小 | 推奨 |
|---|---|---|
| OS | Windows 10 / macOS 13 / Ubuntu 20.04 | Windows 11 / macOS 14+ / Ubuntu 22.04 |
| GPU | NVIDIA GTX 1660 6GB / Apple M1 | NVIDIA RTX 4070 12GB 以上 / Apple M2 Pro 以上 |
| VRAM | 4GB(SD1.5、省メモリ) | SDXL は12GB以上推奨 |
| システムRAM | 8GB | 32GB(SDXL・拡張多用時) |
| ストレージ | 10GB(本体+SD1.5モデル1個) | 500GB以上のNVMe SSD(モデル多数保管) |
| Python | 3.10.6(必須・厳守) | 3.10.6 |
モデルファイルはSD1.5で約2〜7GB、SDXLで約6〜7GB、マージモデルやLoRAを集め始めると数百GBは簡単に消費します。最初から大容量NVMe SSDを用意しておくと後悔しません。
インストール手順
最大の注意点を先に述べます。A1111はPython 3.10.6でなければ正常に動きません。3.11や3.12、3.13ではPyTorch関連で起動に失敗します。Anacondaの混在環境も事故の元なので、専用のPython 3.10.6をシステムに入れるか、後述のリリースパッケージ(埋め込みPython同梱)を使ってください。
Windows(リリースパッケージ・初心者に最も推奨)
もっとも失敗が少ないのが、公式が用意した sd.webui.zip を使う方法です。Pythonのインストールすら不要で、埋め込みPythonが同梱されています。
# 1. ブラウザで以下URLを開き sd.webui.zip をダウンロード
# https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
# 2. 任意のフォルダ(パスに日本語・スペースを含めない。例: C:\sd)に展開
# 3. PowerShell で展開先に移動
cd C:\sd\sd.webui
# 4. 依存関係とWebUI本体を最新版に更新
.\update.bat
# 5. WebUIを起動(初回はモデルやライブラリのダウンロードで時間がかかる)
.\run.bat起動が完了すると http://127.0.0.1:7860 が自動で開きます。開かない場合は手動でブラウザにこのURLを入力してください。
Windows(git clone・拡張機能を本格運用する人向け)
拡張機能を多用したり、自分でアップデート管理をしたい場合はgitクローン方式が便利です。
# 1. Python 3.10.6 を公式からインストール(インストール時に Add to PATH にチェック)
# https://www.python.org/downloads/release/python-3106/
# 2. Git for Windows をインストール
# https://git-scm.com/download/win
# 3. 任意のフォルダでクローン(C:\ 直下など浅い階層を推奨)
cd C:\
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
# 4. webui-user.bat を管理者でない通常ユーザーで実行
.\webui-user.bat初回起動時にvenv(仮想環境)の作成、PyTorch、xformers等が自動ダウンロードされます。回線にもよりますが10〜30分かかります。
Linux(Ubuntu / Debian)
# 1. 依存パッケージをインストール
sudo apt update
sudo apt install -y wget git python3 python3-venv libgl1 libglib2.0-0
# 2. NVIDIAドライバとCUDAが入っていることを確認
nvidia-smi
# 3. インストールスクリプトを実行(初回はvenv作成と依存DLが走る)
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
chmod +x webui.sh
./webui.shシステムのPythonが3.10系でない場合は、webui-user.sh 内の python_cmd にPython 3.10.6のパスを明示指定してください。Red Hat系は sudo dnf install wget git python3 gperftools-libs libglvnd-glx、Arch系は sudo pacman -S wget git python3 で依存を入れます。
macOS(Apple Silicon / M1・M2・M3・M4)
Apple SiliconではMetal(MPS)バックエンドで動作します。NVIDIA GPUより低速ですが、SD1.5なら実用域です。
# 1. Homebrew をインストール(未導入の場合)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 2. 必要パッケージ
brew install cmake protobuf rust python@3.10 git wget
# 3. クローンして起動
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui
./webui.sh公式の最新手順はApple Silicon向けインストールWikiに掲載されています。Intel Mac(dGPUなし)は実用速度が出ないため非推奨です。
RTX 50シリーズ(Blackwell / RTX 5070・5080・5090)での注意
A1111本体が同梱するPyTorchはBlackwell世代のCUDA Compute Capability(sm_120)に対応していないため、そのままでは起動できないか「no kernel image is available」エラーになります。対処は次のいずれかです。
- 推奨: 本体ではなく reForge や Forge Classic など、新GPUに対応したフォークを使う
- A1111を使い続ける場合は、venv内のPyTorchをCUDA 12.8対応のnightly版へ手動更新する(下記)
# venvを有効化してからPyTorchをCUDA 12.8対応版に差し替え
.\venv\Scripts\activate
pip uninstall -y torch torchvision
pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cu128初期設定
初回起動の前に、最低1つチェックポイントモデルが必要です。Hugging Face や CivitAI から .safetensors 形式のSD1.5またはSDXLモデルを入手し、以下のフォルダに置きます。
# チェックポイントの配置先
stable-diffusion-webui/models/Stable-diffusion/
# VAE(必要な場合)
stable-diffusion-webui/models/VAE/
# LoRA
stable-diffusion-webui/models/Lora/起動オプション(webui-user.bat / webui-user.sh)
VRAMやGPUに応じて起動引数を COMMANDLINE_ARGS に設定します。Windowsは webui-user.bat、Linux/Macは webui-user.sh を編集します。
# 例: webui-user.bat の該当行
set COMMANDLINE_ARGS=--xformers --medvram --autolaunch --api
# 主なオプションの意味
# --xformers : メモリ削減・高速化(NVIDIA推奨)
# --medvram : VRAM 6〜8GB向けの省メモリモード
# --lowvram : VRAM 4GB向け(低速)
# --autolaunch : 起動時にブラウザを自動で開く
# --api : REST API を有効化(外部連携用)
# --listen : LAN内の他端末からアクセス可能にする日本語化
WebUIは英語UIですが、拡張機能で日本語化できます。Extensions タブ → Available → Load from をクリックし、一覧から ja_JP Localization をインストール。その後 Settings → User interface → Localization で ja_JP を選び、Apply settings と Reload UI を実行します。
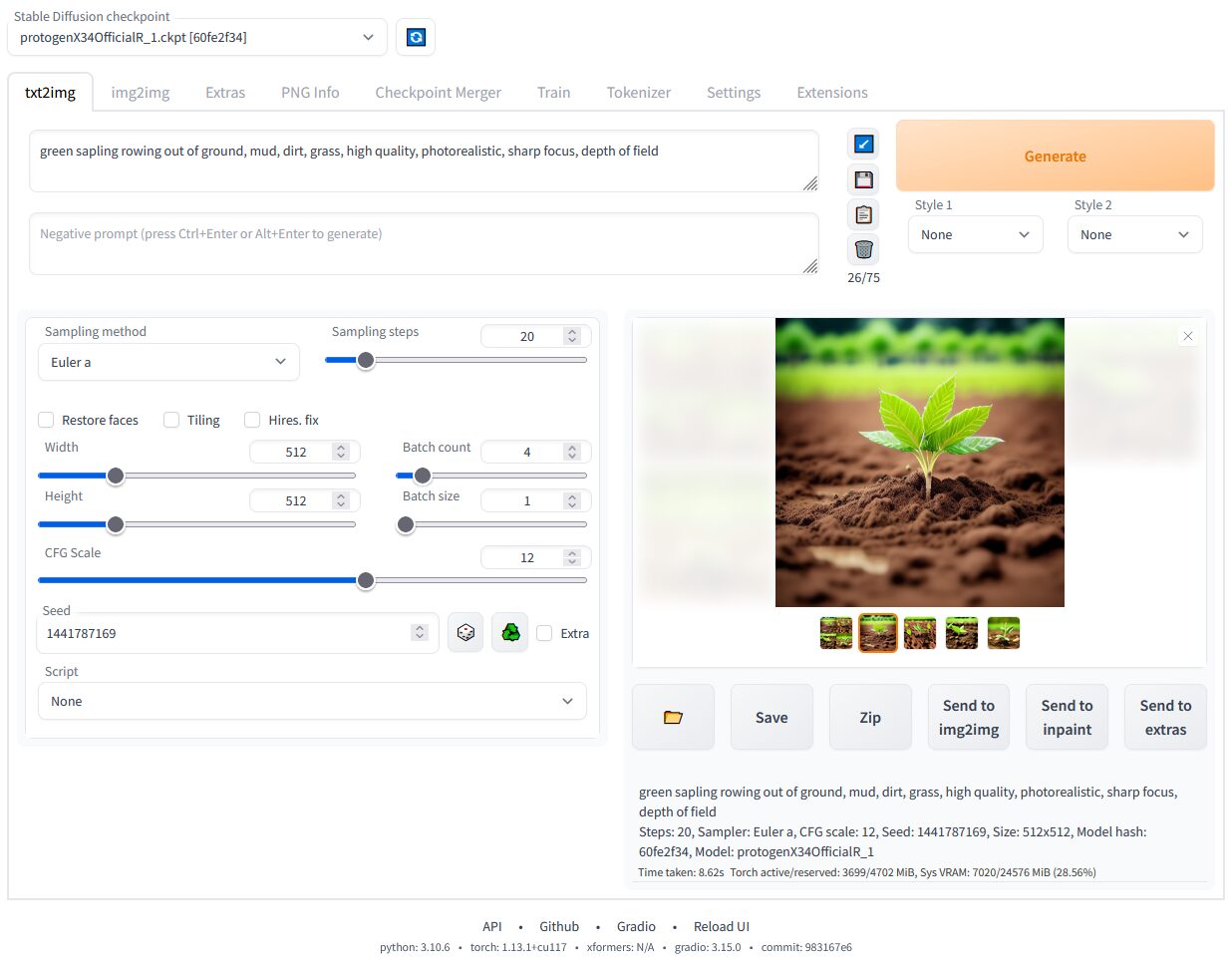
基本的な使い方
txt2img(テキストから画像生成)
もっとも基本的な機能です。以下の手順で最初の1枚を生成できます。
- 画面左上の
Stable Diffusion checkpointで使用モデルを選択 txt2imgタブで上のプロンプト欄に生成したい内容を英語で入力(例:masterpiece, best quality, 1girl, cherry blossom, spring, soft lighting)- 下のネガティブプロンプト欄に避けたい要素を入力(例:
worst quality, low quality, blurry, bad anatomy) Sampling methodはDPM++ 2M Karras、Sampling stepsは20〜30が標準Width/HeightはSD1.5なら512×768、SDXLなら1024×1024が基準CFG Scaleは7前後(プロンプトへの忠実度)- 右の
Generateボタンをクリック
プロンプトの書き方の基本
生成品質はプロンプト設計でほぼ決まります。A1111では以下の文法を覚えておくと制御が一気に楽になります。
- 強調:
(word:1.3)で重み1.3倍、(word:0.7)で弱める。括弧(word)だけなら1.1倍 - プロンプト編集:
[cat:dog:0.5]は生成の前半50%をcat、後半をdogとして描く - BREAK:
BREAKを挟むとそこで条件を区切り、要素の混ざりを防ぐ - 順序: 先頭に書いた語ほど強く反映される。
masterpiece, best qualityを冒頭に置くのが定石 - ネガティブ:
worst quality, low quality, bad anatomy, extra fingers, watermarkをテンプレ化しておく
Embedding(Textual Inversion)形式のネガティブ用ファイル(EasyNegative 等)を embeddings/ に置き、ネガティブ欄にファイル名を書くだけで品質が安定するため、人物生成では広く使われています。
img2img(画像から画像生成)
img2img タブに元画像をドラッグ&ドロップし、プロンプトを入力して生成します。Denoising strength が重要で、0.3前後で元画像をほぼ維持、0.7以上で大きく変化します。線画への着色や写真のイラスト化に使います。
インペイント(部分修正)
img2img → Inpaint で画像の一部をマスク(ブラシで塗る)し、その部分だけを再生成します。手の崩れ修正、不要物の除去、衣装の差し替えなどに必須の機能です。Mask blur と Inpaint area: Only masked の組み合わせで自然な合成ができます。
実践的な使い方
ケース1: LoRAでキャラクター・画風を固定する
CivitAIなどで入手したLoRAファイル(.safetensors)を models/Lora/ に置き、プロンプト欄で Lora タブから対象をクリックすると <lora:ファイル名:0.8> という記述が挿入されます。末尾の数値(0.8)が適用強度です。画風が強すぎる場合は0.5〜0.7に下げ、トリガーワード(モデル配布ページに記載)を併記すると安定します。
ケース2: ControlNetでポーズ・構図を制御する
もっとも実用価値の高い拡張機能です。Extensions → Install from URL に以下を入力してインストールします。
https://github.com/Mikubill/sd-webui-controlnetインストール後、ControlNetモデル(OpenPose、Canny、Depth、Lineart等)を extensions/sd-webui-controlnet/models/ に配置します。txt2img画面下部の ControlNet パネルに参照画像を入れ、Preprocessor と Model を選ぶと、その骨格・輪郭・深度を保ったまま別の絵柄で再生成できます。
ケース3: 高解像度化(Hires. fix とアップスケール)
txt2imgで小さく生成してから Hires. fix にチェックを入れると、一度生成した画像をアップスケーラー(R-ESRGAN 4x+ 等)で拡大しつつ細部を描き直します。Upscale by は1.5〜2.0、Denoising strength は0.3〜0.5が破綻しにくい設定です。完成画像をさらに拡大したい場合は Extras タブで後処理アップスケールを行います。
応用・カスタマイズ
必須級の拡張機能
- ADetailer: 顔・手を自動検出して個別に高精細化。人物生成では事実上必須
- Regional Prompter: 画面を領域分割し、領域ごとに別プロンプトを適用
- Dynamic Prompts: ワイルドカードでプロンプトをランダム生成し、バリエーション量産
- Ultimate SD Upscale: タイル分割で超高解像度(4K以上)アップスケール
- tagcomplete: Danbooruタグの入力補完。プロンプト作成効率が劇的に向上
拡張機能は Extensions → Install from URL にGitHubのURLを貼り付け、Apply and restart UI で導入します。更新は Extensions → Installed → Check for updates から行えます。
API経由での自動生成
--api 付きで起動すると、HTTP経由で生成を自動化できます。バッチ処理や自作アプリとの連携に便利です。
import requests, base64
payload = {
"prompt": "masterpiece, best quality, 1girl, autumn forest",
"negative_prompt": "worst quality, low quality",
"steps": 25,
"width": 512,
"height": 768,
"cfg_scale": 7,
"sampler_name": "DPM++ 2M Karras",
}
r = requests.post("http://127.0.0.1:7860/sdapi/v1/txt2img", json=payload)
img = r.json()["images"][0]
with open("output.png", "wb") as f:
f.write(base64.b64decode(img))
print("saved output.png")パフォーマンス最適化
- xformersを有効化:
--xformersでアテンション計算を高速化しVRAMも削減。NVIDIAなら最優先で設定 - VRAMに応じた省メモリ設定: 12GB以上なら無指定、6〜8GBは
--medvram、4GBは--lowvram - SDXL利用時は
--medvram-sdxl: SDXLのときだけ省メモリにし、SD1.5は高速のまま - Token Mergingを使う:
Settings→OptimizationsのToken merging ratioを0.2〜0.5にすると体感速度が向上 - VAEをfp16にする:
SettingsでVAE精度を調整するとVRAMピークを抑えられる - 不要な拡張を無効化: 起動が重い・生成が遅い場合、まず拡張を全無効化して切り分ける
それでも速度・VRAMに不満がある場合、同じGPUでもForge系に乗り換えるだけで体感1.3〜2倍高速・省メモリになるのが2026年の実情です。A1111で操作に慣れたら、Forge Classicやreforgeへの移行を検討する価値は十分あります。
よくあるエラーとトラブルシューティング
1. 起動時に「torch is not able to use GPU」エラー
GPUドライバが古いか、Pythonバージョンが3.10系でないことが主因です。nvidia-smi でドライバを確認し、Pythonを3.10.6に統一してください。それでも解決しない場合はvenvフォルダを削除して再生成します。
2. RTX 50シリーズで「no kernel image is available for execution」
同梱PyTorchがBlackwell(sm_120)非対応のため発生します。前述の通りCUDA 12.8対応のnightly PyTorchへ差し替えるか、新GPU対応のreForge/Forge Classicへ移行します。これはA1111本体が更新停止していることに起因する構造的な問題です。
3. 生成画像が真っ黒・NaNエラー
VAEや一部GPUで起こる既知の不具合です。起動オプションに --no-half-vae を追加します。GTX 16xxシリーズでは --no-half --precision full も併用すると安定します。
4. 「Couldn’t install torch」「pip install failed」
初回のPyTorchダウンロードがネットワーク不調で失敗するケースです。venvフォルダを削除し、回線を変えて再実行します。社内プロキシ環境ではプロキシ設定(HTTP_PROXY / HTTPS_PROXY)が必要です。
5. 拡張機能を入れたらUIが起動しなくなった
拡張同士の競合か、A1111本体が古くて拡張の要求バージョンに合わないのが原因です。extensions フォルダ内の該当拡張フォルダを手動削除して起動し直します。A1111本体が更新停止しているため、新しい拡張ほどこの問題が起きやすい点に注意してください。
6. SDXLでメモリ不足(CUDA out of memory)
SDXLはSD1.5の倍以上のVRAMを使います。--medvram-sdxl を付与し、生成解像度を1024×1024以下、バッチサイズを1にします。それでも足りなければForge系の方がSDXLの省メモリ性能が高いため移行を検討します。
7. 「No such file or directory: ‘ui-config.json’」など設定ファイル破損
異常終了後に設定ファイルが壊れることがあります。ui-config.json や config.json をリネーム退避してから再起動すると、デフォルト設定で再生成されます。設定はやり直しになりますが起動不能は解消します。
8. 生成が極端に遅い(1枚に数分かかる)
GPUではなくCPUで動作している典型例です。起動ログに Running on CPU と出ていないか確認します。--xformers 未指定、省メモリオプションの付けすぎ(不要に --lowvram を付けている)、他プロセスがVRAMを占有しているケースも多いため、nvidia-smi でVRAM使用状況を確認してください。
以前のバージョンとの違い・廃止された仕様
古い日本語記事を参照するとハマりやすい変更点を整理します。
- モデル形式: かつて主流だった
.ckptは任意コード実行リスクがあるため、現在は.safetensorsが事実上の標準。新しいモデルはほぼsafetensorsで配布されます - サンプラー名の変更: 旧
Euler a等は健在ですが、v1.10でDDIM CFG++やAlign Your Steps等が追加。古い記事の「おすすめサンプラー」は最新の選択肢を欠いています - SD2.x系: 一時期使われたSD2.0/2.1はコミュニティでほぼ廃れ、現在はSD1.5かSDXLの二択が現実的
- xformersの位置づけ: 以前は必須級でしたが、PyTorchのSDPA最適化が進み、環境によっては
--opt-sdp-attentionでも十分な速度が出ます - FLUX/SD3.5: これらは本体未対応。「A1111でFLUXを動かす」と書かれた古い情報は本体ではなくForge系の話である点に注意
おすすめの組み合わせ・連携
- A1111 + CivitAI: モデル・LoRA・作例プロンプトの宝庫。ライセンス(特に商用可否)は必ず確認
- A1111 + ControlNet + ADetailer: 構図制御と顔・手の自動高精細化。人物生成の鉄板構成
- A1111(学習用)→ Forge Classic / reForge(実運用): 仕組みはA1111で学び、速度と新モデル対応はForge系で得る2段構え
- A1111 API + 自作スクリプト: 大量バリエーション生成やWebサービス組み込み
- A1111 + ローカルLLM: Ollama(2026年5月時点でも月次更新が続く活発なプロジェクト)でプロンプトを自動生成し、A1111のAPIに渡す自動化も人気です
推奨PCスペック
用途別に3段階で示します。Stable Diffusionは生成画像のVRAM消費が大きいため、GPUのVRAM容量が最重要です。
| レベル | 用途 | GPU | RAM | ストレージ |
|---|---|---|---|---|
| 入門 | SD1.5中心・学習目的 | RTX 4060 8GB | 16GB DDR5 | 1TB NVMe SSD |
| 標準 | SDXL・LoRA・拡張多用 | RTX 4070 Ti SUPER 16GB | 32GB DDR5 | 2TB NVMe SSD |
| ハイエンド | SDXL大量生成・将来のFLUX運用(Forge系) | RTX 5090 32GB | 64GB DDR5 | 4TB NVMe SSD |
SD1.5だけならVRAM 8GBで快適に動きます。SDXLを本格運用するなら12GB以上、できれば16GBを推奨します。将来FLUX等の新世代モデル(A1111本体非対応のためForge系で運用)まで視野に入れるなら、最初から24GB以上のGPUにしておくと長く使えます。
まとめ
Stable Diffusion WebUI(AUTOMATIC1111)は、2026年5月時点でも「Stable Diffusionを学ぶ最初の一歩」として依然ベストの選択肢です。圧倒的な日本語情報量、最大規模の拡張機能エコシステム、シンプルなUIにより、画像生成AIの基礎を体系的に習得できます。SD1.5・SDXLという枯れたモデルを使う限り、安定して実用に耐えます。
一方で本記事で繰り返し述べた通り、A1111本体の開発は2024年7月のv1.10.0以降ほぼ停止しており(最新タグはv1.10.1)、FLUXやSD3.5、RTX 50シリーズへの正式対応はありません。新世代モデルや最新GPUをフルに使いたい場合は、A1111互換でメンテナンスが継続している Forge Classic や reForge、あるいは活発に開発が続く SD.Next・ComfyUI(v0.21.1、2026年5月)への移行を検討してください。
結論として2026年のおすすめは、「A1111で仕組みと操作を学び、実運用はForge系へ」という2段構えです。UIがほぼ同じForge系なら移行コストはほとんどかかりません。本記事をブックマークし、インストールから拡張運用、そして次の一手までの道筋として活用してください。最新の公式情報はAUTOMATIC1111公式リポジトリと公式Wikiで確認できます。
📦 この記事で紹介した商品
- Stable Diffusion画像生成ガイドブック → Amazonで見る
- NVIDIA GeForce RTX 4070 Ti SUPER → Amazonで見る
- NVIDIA GeForce RTX 5090 → Amazonで見る
- Crucial PRO (Made by Micron) Desktop Memory 32GBx2 DDR5-5600 Limited Lifetime… → Amazonで見る
- Nextorage 1TB M.2 SSD 高速 7400MB/s PS5 → Amazonで見る
※ 上記リンクはAmazonアソシエイトリンクです。購入いただくと当サイトに紹介料が入ります。

